 XfyCoding博客
XfyCoding博客Java并发容器总结
前言
我们日常开发会经常用到各种容器类,容器类为我们提供了大量简化数据操作的API,提高了我们的数据处理的效率。 虽然说容器类使用十分方便,但是在多线程情况下,容器类使用不当可能导致线程安全问题,所以Java设计者们为我们提供线程安全操作的并发容器类解决这些问题。 但是使用并发容器就真的完全可以避免线程安全问题了吗?它们使用的几个注意事项不知道你是否了解过,这篇文章我们就会基于Map和List两个比较常用的容器类来展开问题的探讨。
HashMap存在的线程安全问题
JDK7版本源码解析
jdk7版本的hashMap底层采用数组加链表的形式存储元素,假如需要存储的键值对经过计算发现存放的位置已经存在键值对了,那么就是用头插法将新节点插入到这个位置。
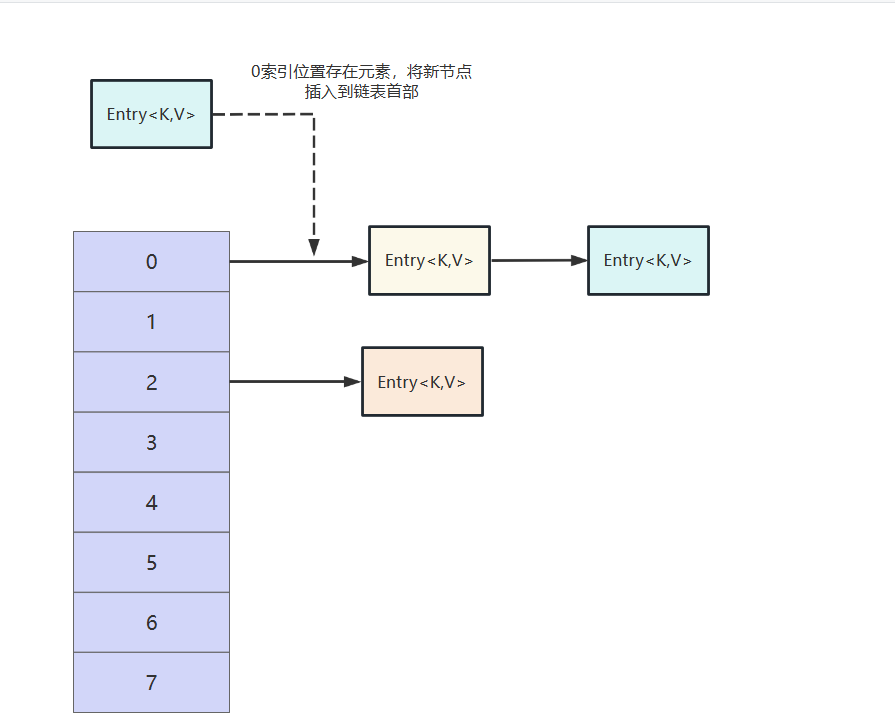
这一点,我们可以在其put方法中得到印证,它会根据key计算获得元素应该存放的位置,如果位置为空则直接调用addEntry插入,如果位置不为空,则看看这个索引位置的数组是否存在一样的key,若有则覆盖value并返回。如果遍历当前索引的整条链表都没有一样的key,则通过头插法将元素添加到链表首部。
public V put(K key, V value) {
if(table == EMPTY_TABLE) {
inflateTable(threshold);
}
if(key == null) return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
//得到元素要存储的位置table[i],如果位置不为空则进行key比对,若一样则进行覆盖操作并返回,反之继续向后遍历,直到走到链表尽头为止
for(Entry < K, V > e = table[i]; e != null; e = e.next) {
Object k;
//如果key值和要存储的key一模一样,则进行覆盖操作,将e的value修改为传入的value即可
if(e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//走到这里说明要在一个空的位置添加节点,将modCount自增,并调用addEntry完成新节点插入
modCount++;
addEntry(hash, key, value, i);
return null;
}addEntry就是完成元素的插入的具体实现,它会判断数组是否需要扩容,然后通过头插法将节点插入。
void addEntry(int hash, K key, V value, int bucketIndex) {
//查看数组是否达到阈值,若达到则进行扩容操作
if((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//使用头插法将节点插入
createEntry(hash, key, value, bucketIndex);
}CPU100%问题
JDK7版本的hashMap在多线程情况下进行扩容操作很可能会导致CPU 100%问题,对此我们不妨从源码的角度来排查并重现这个问题
还记得我们上文说明HashMap的put操作时提到的扩容方法resize嘛?它的具体实现如下,可以看到它会根据newCapacity创建一个新的容器newTable ,然后将原数组的元素通过transfer方法转移到新的容器newTable中。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if(oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//创建新的容器
Entry[] newTable = new Entry[newCapacity];
//将旧的容器的元素转移到新数组中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int) Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}再来看看transfer的逻辑,这里涉及到链表元素的转移操作,概括一下这段代码大概做以下这几件事情:
- 记录要被转移节点的后继节点
- 计算该节点存放到newTable的索引位置i
- 将该节点的next指针指向newTable的i位置的元素
- newTable的i位置的指针指向这个节点
- e指向next所指节点,循环上述操作,直到旧数组中的链表全部遍历完成。
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for(Entry < K, V > e: table) {
while(null != e) {
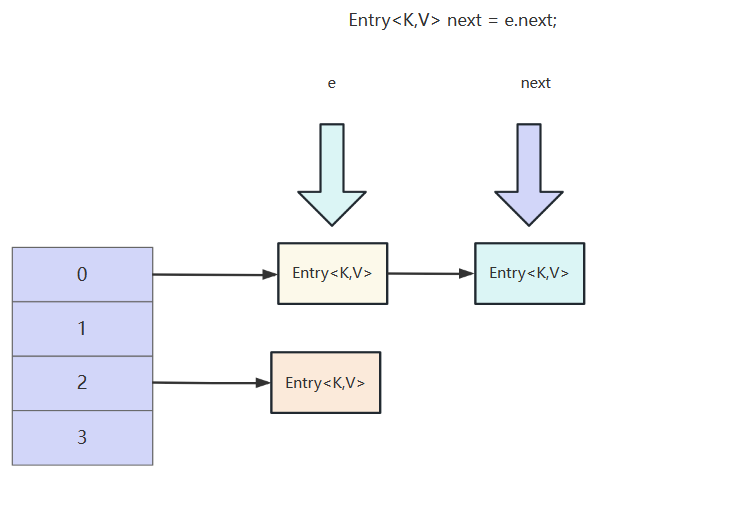
//记录要被转移到新数组的e节点的后继节点
Entry < K, V > next = e.next;
if(rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//计算e节点要存放的新位置i
int i = indexFor(e.hash, newCapacity);
//e的next指针指向i位置的节点
e.next = newTable[i];
//i位置的指针指向e
newTable[i] = e;
//e指向后继,进行下一次循环转移操作
e = next;
}
}
}通过代码了解整体过程之后,我们不妨通过画图的方式来了解一下这个过程。
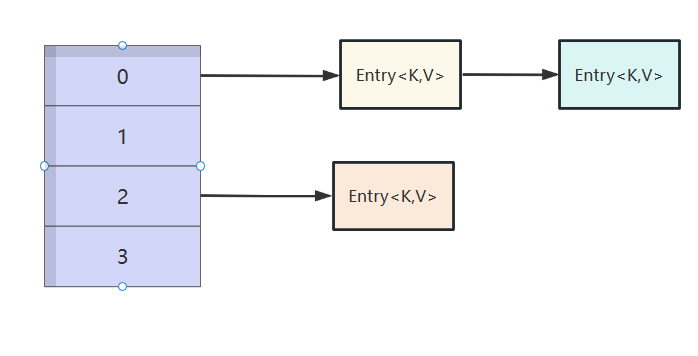
我们插入下一个元素到0索引位置时发现,0索引位置的元素个数已经等于阈值2,触发扩容。
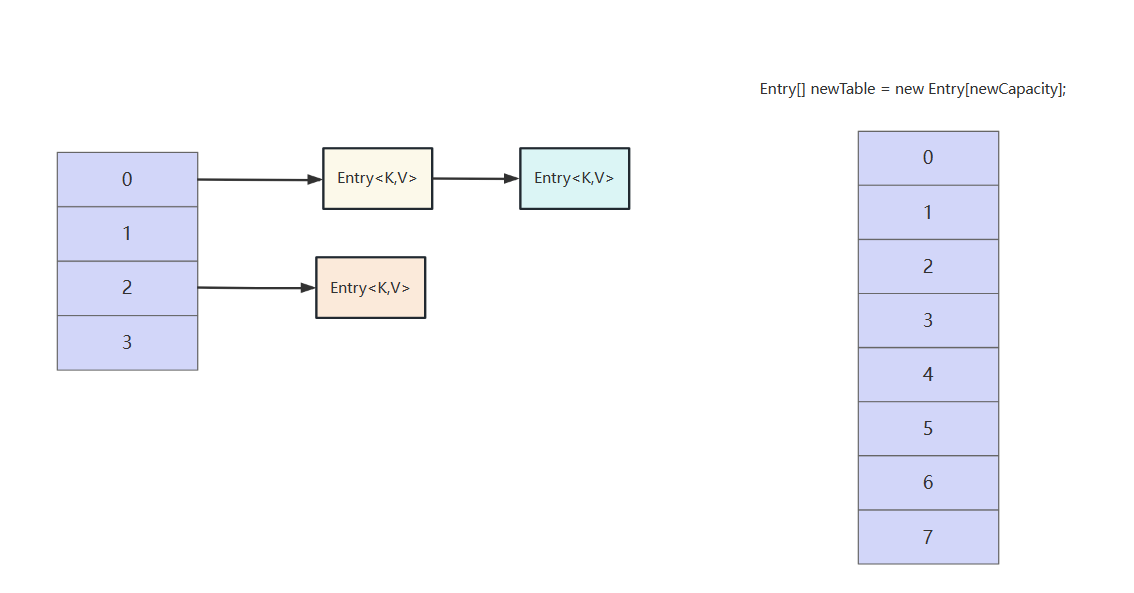
于是创建了一个两倍原数组大小的新数组
在迁移前,用e和next两个指针指向旧容器的元素
经过再哈希计算,索引0位置的元素存到新数组的索引为3
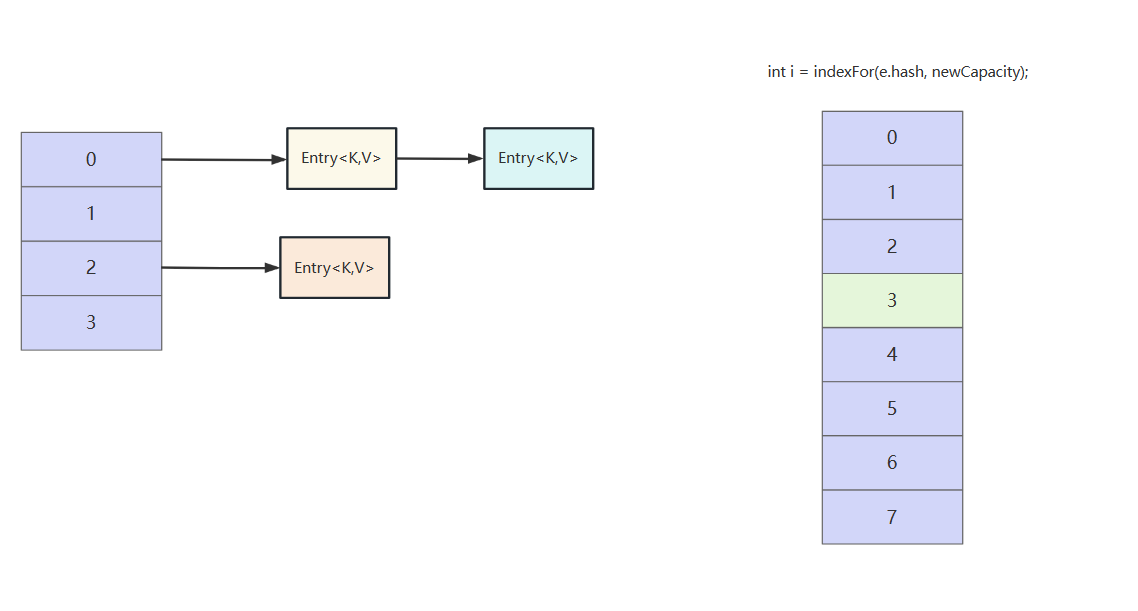
e的next域指向新数组的i位置的元素,因为此时新数组i位置还没有存放任何元素所以指向的就是头节点。
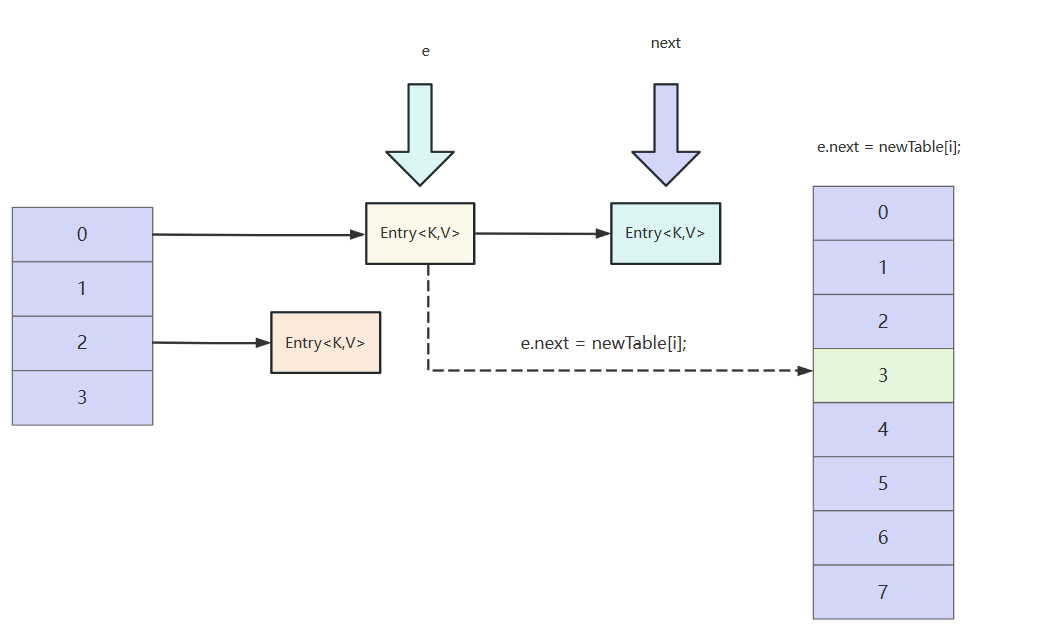
重点来了新数组i索引位置的指针指向e,此时e从逻辑上就相当于存到新数组中了。
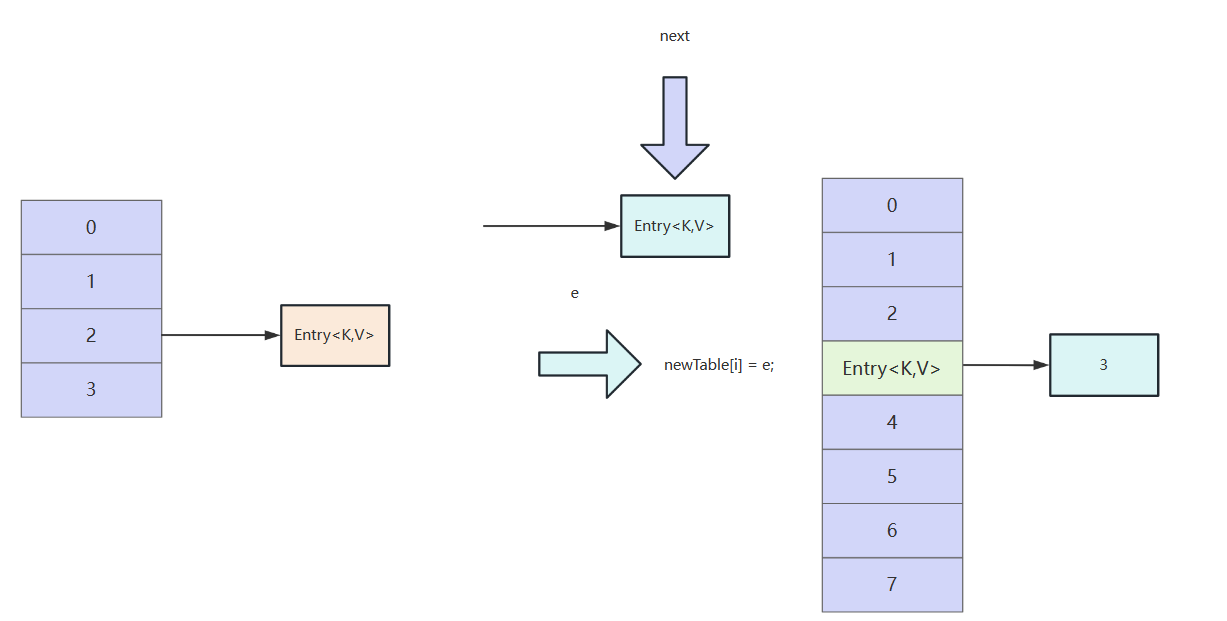
然后e指向next元素,进入下一次循环
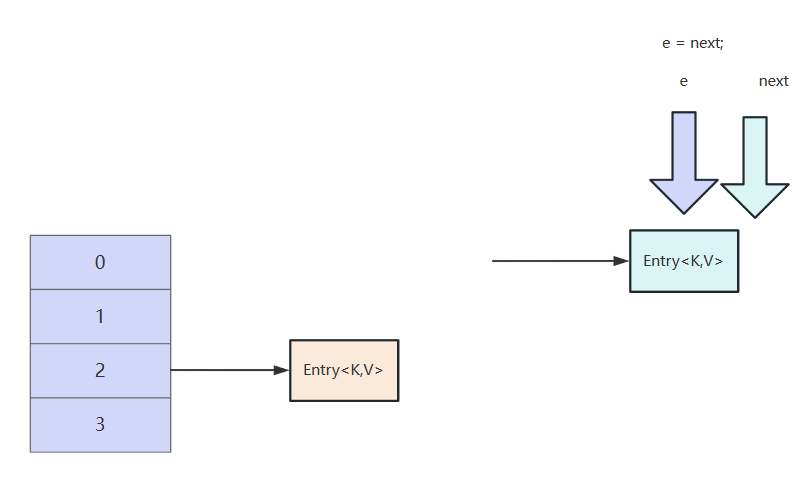
因为当前这e没有后继节点,所以next为null
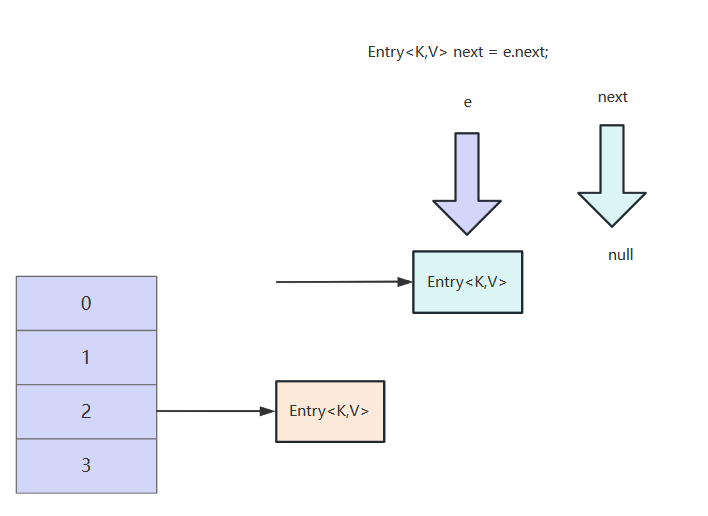
当前e节点经过计算,位置也是在3索引,所以next域指向3索引头节点。
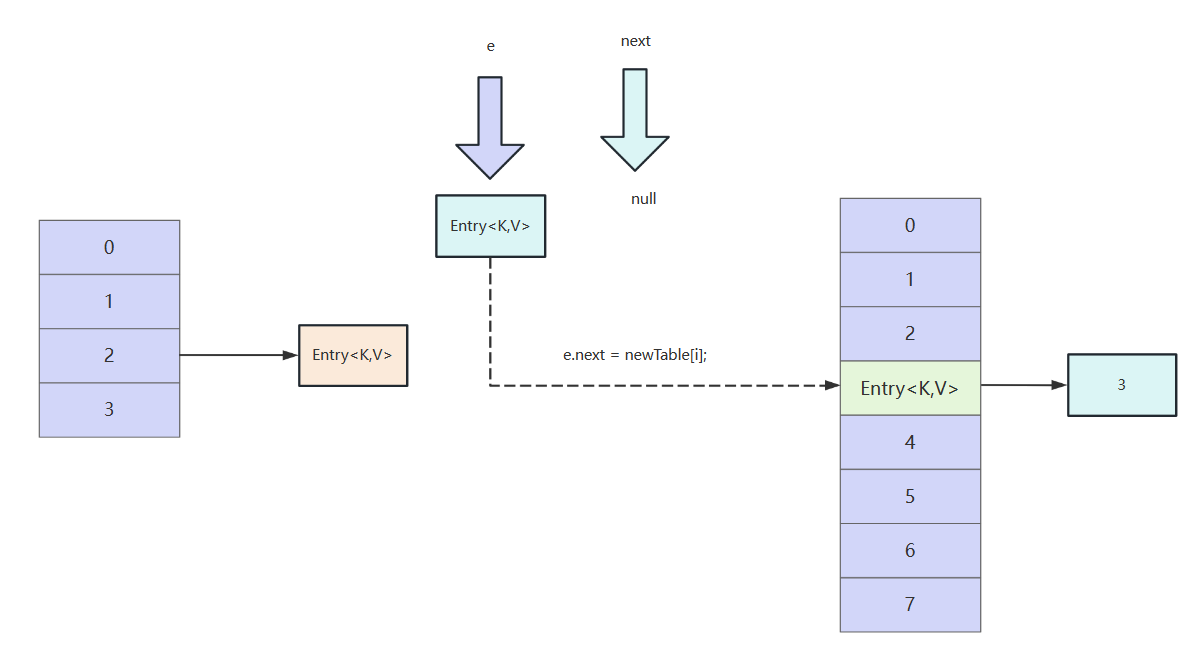
新数组的i索引的指针指向当前e节点,完成有一次节点迁移,本次迁移完成。循环发现下一个e为null,结束循环。继续旧的数组其他索引位置的节点数据迁移。
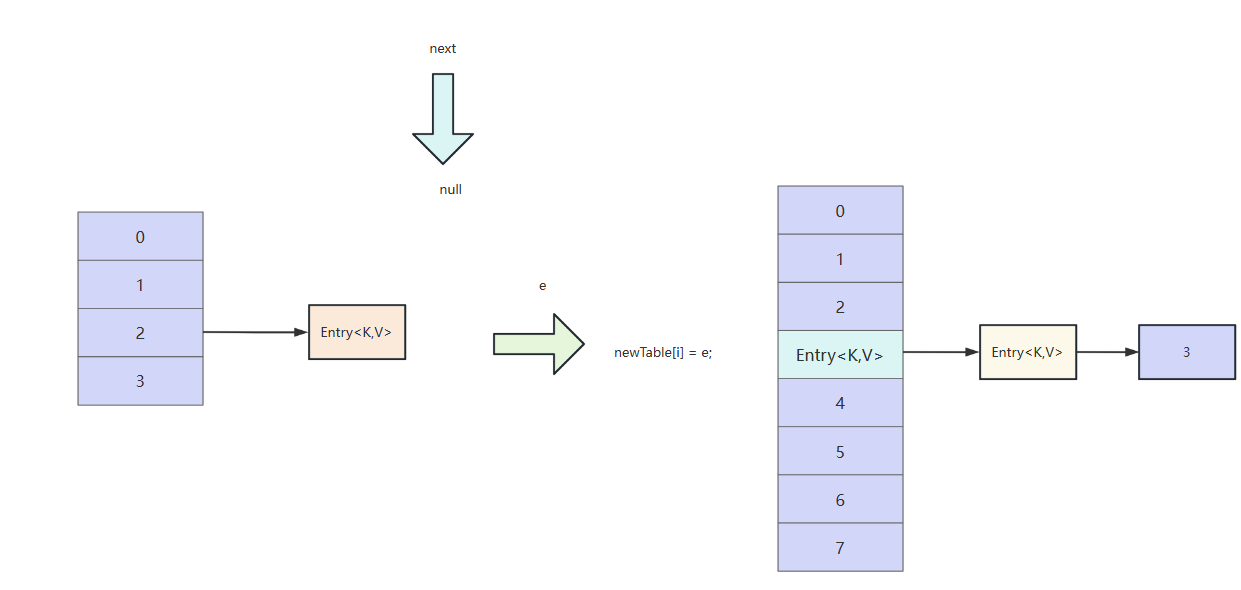
当我们了解了JDK7版本的hashMap扩容过程之后,我们就从多线程角度看看什么时候会出现问题,我们不妨想象有两个线程同时在执行多线程操作。
我们假设线程1,执行到Entry<K,V> next = e.next;时线程被挂起,此时线程1的新容器和旧容器如下图所示:
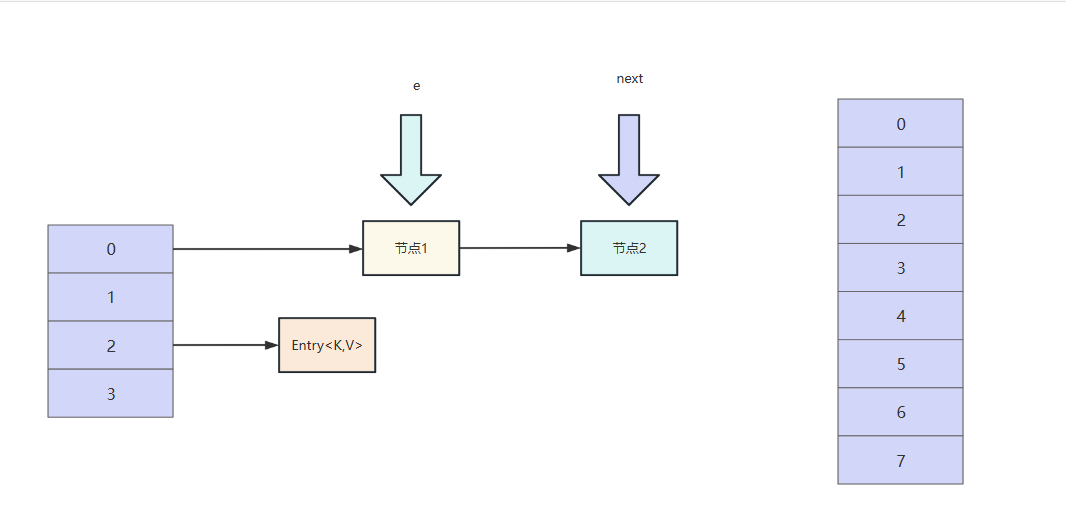
此时线程2获得执行权,它的e和next同样指向节点1和节点2

按照我们上文的关于jdk7的hashMap扩容操作,我们的节点1和节点2会按照头插法存到索引3的位置,最终效果如下
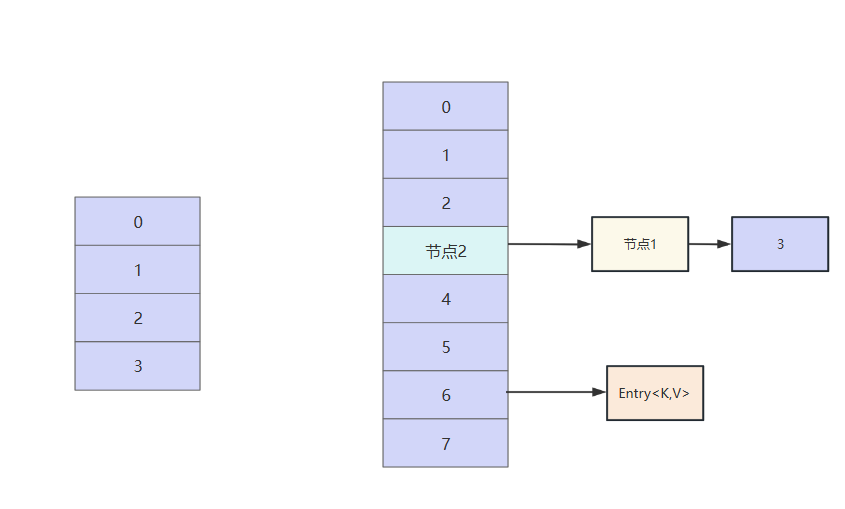
此时线程1再次获得执行权,e指向节点1,next还是指向节点2。我们不妨按照代码的逻辑继续往下走看看。
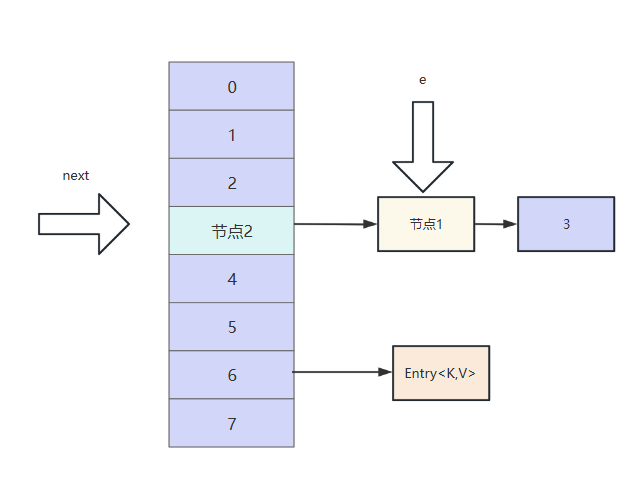
首先e的next域指向头节点,此时节点1的next指针指向节点2,可以看到此时节点2和节点1构成另一个环,我们不妨继续往下走。
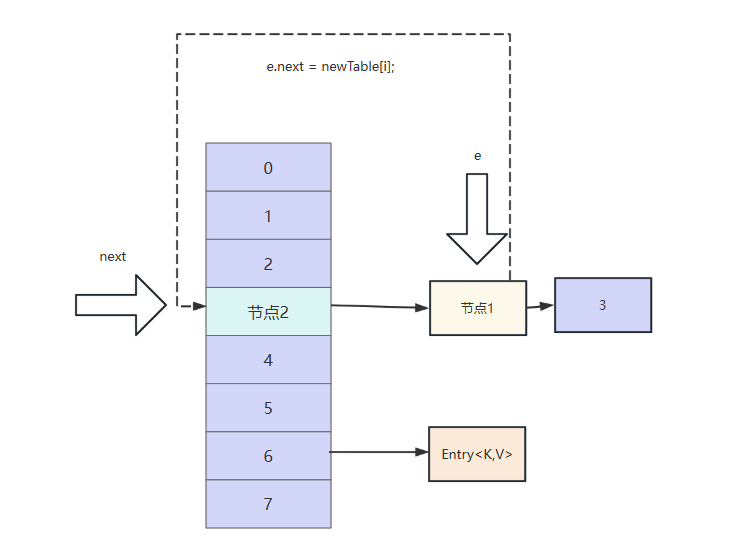
然后节点1头插法插入到节点2前面
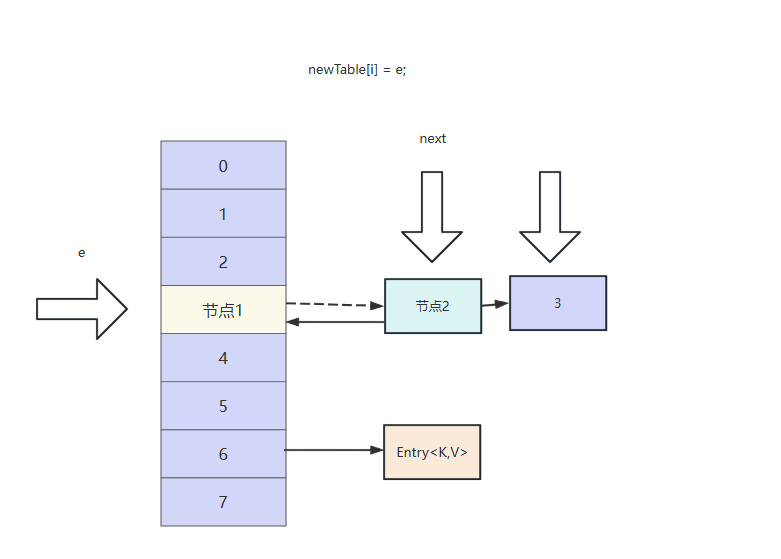
然后e指向next,即指向节点2。
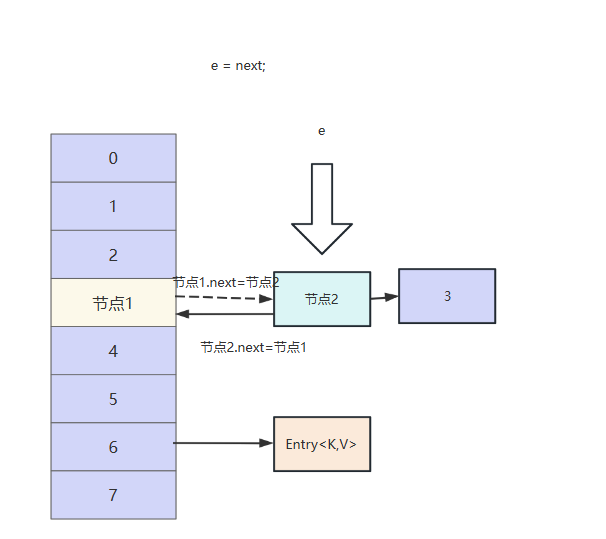
此时next再次指向节点1,逻辑再次回到的线程1刚刚拿到执行权的样子,构成一个死循环,最终导致CPU100。
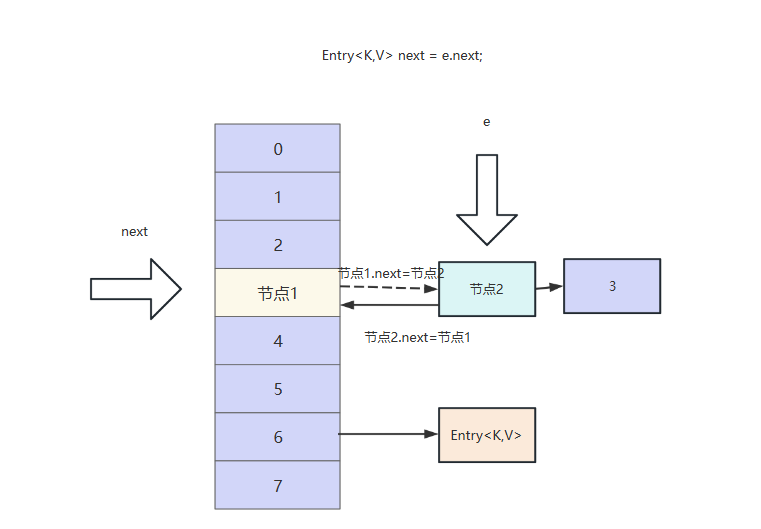
通过图解我们得知CPU100%原因之后,我们不妨通过代码来重现这个问题。
首先我们将项目JDK版本设置为JDK7。然后定义一个大小为2的map,阈值为1.5,这也就以为着插入时看到size为3的时候会触发扩容。
/**
* 这个map 桶的长度为2,当元素个数达到 2 * 1.5 = 3 的时候才会触发扩容
*/
private static HashMap<Integer,String> map = new HashMap<Integer,String>(2,1.5f);所以我们的工作代码如下,先插入3个元素,然后两个线程分别插入第4个元素。需要补充一句,这几个元素的key值是笔者经过调试后确定存放位置都在同一个索引上,所以这段代码会触发扩容的逻辑,读者自定义数据样本时,最好和读者保持一致。
try {
map.put(5, "5");
map.put(7, "7");
map.put(3, "3");
System.out.println("此时元素已经达到3了,再往里面添加就会产生扩容操作:" + map);
new Thread("T1") {
public void run() {
map.put(11, "11");
System.out.println(Thread.currentThread().getName() + "扩容完毕 ");
};
}.start();
new Thread("T2") {
public void run() {
map.put(15, "15");
System.out.println(Thread.currentThread().getName() + "扩容完毕 " + map);
};
}.start();
Thread.sleep(60 _000); //时间根据debug时间调整
//死循环后打印直接OOM,思考一下为什么?
//因为打印的时候回调用toString回遍历链表,但此时链表已经成环状了
//那么就会无限拼接字符串
// System.out.println(map);
System.out.println(map.get(5));
System.out.println(map.get(7));
System.out.println(map.get(3));
System.out.println(map.get(11));
System.out.println(map.get(15));
System.out.println(map.size());
} catch(Exception e) {}我们在扩容的核心方法插个断点,断点条件设置为
Thread.currentThread().getName().equals("T1")||Thread.currentThread().getName().equals("T2")并且断点的调试方式改成thread
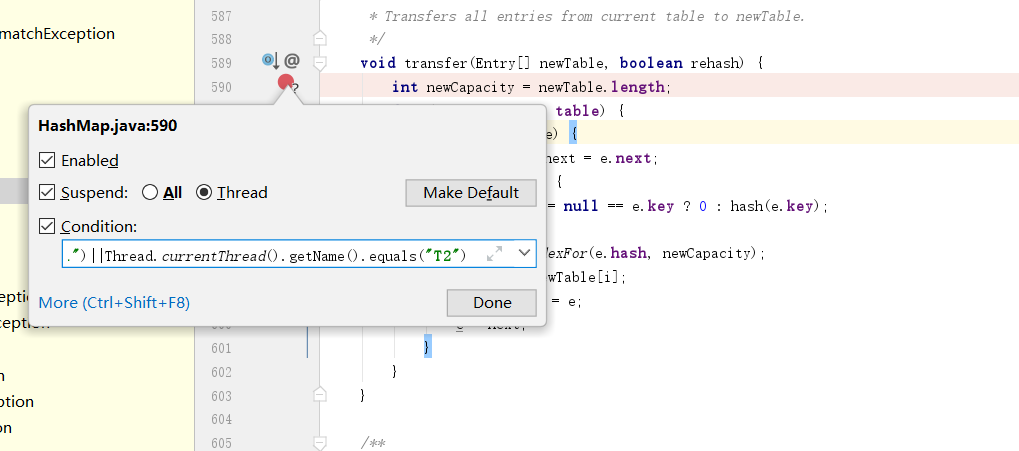
我们首先将线程1断点调试到记录next引用这一步,然后将线程切换为线程2,模拟线程1被挂起。
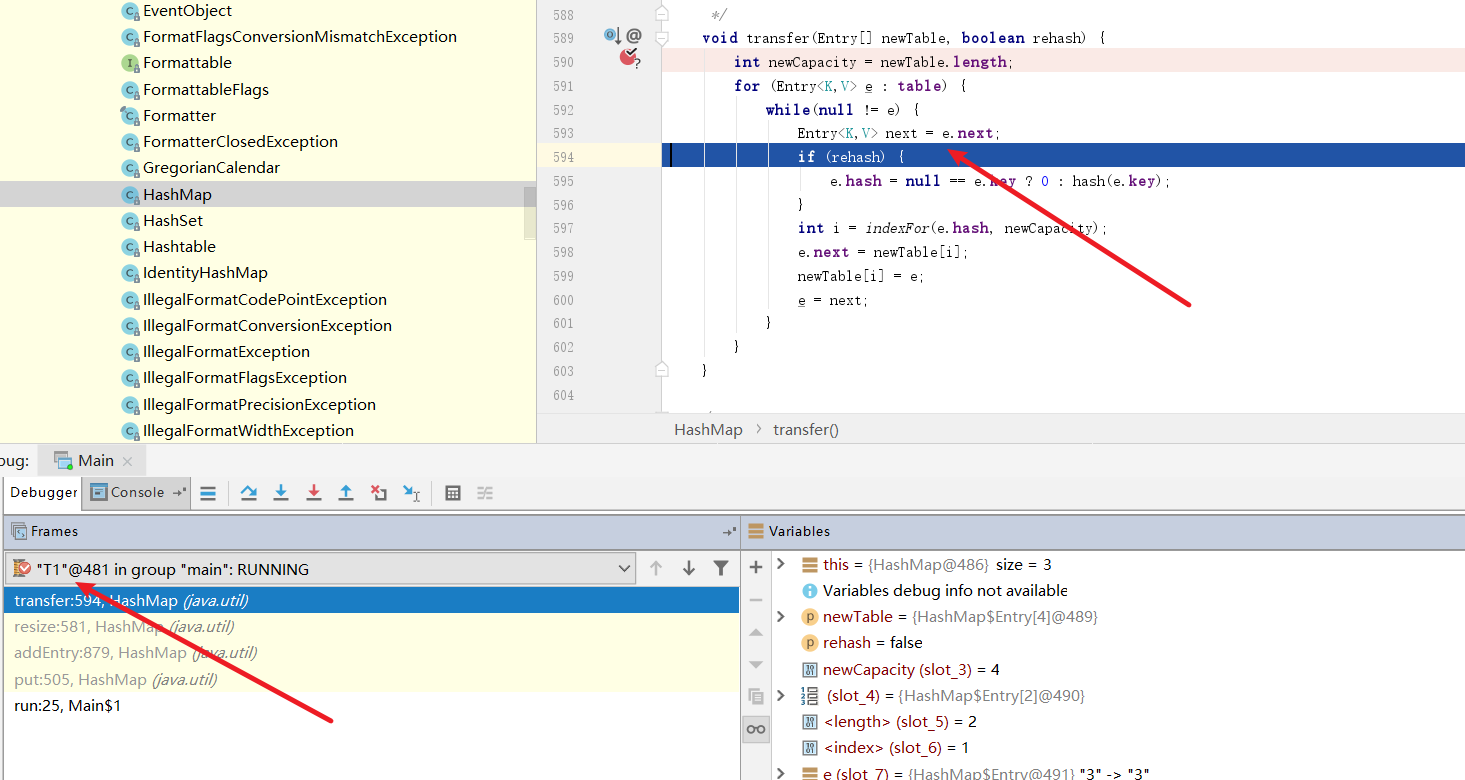
我们直接将线程2走完,模拟线程2完成扩容这一步,然后IDEA会自动切回线程1,我们也将线程1直接走完。
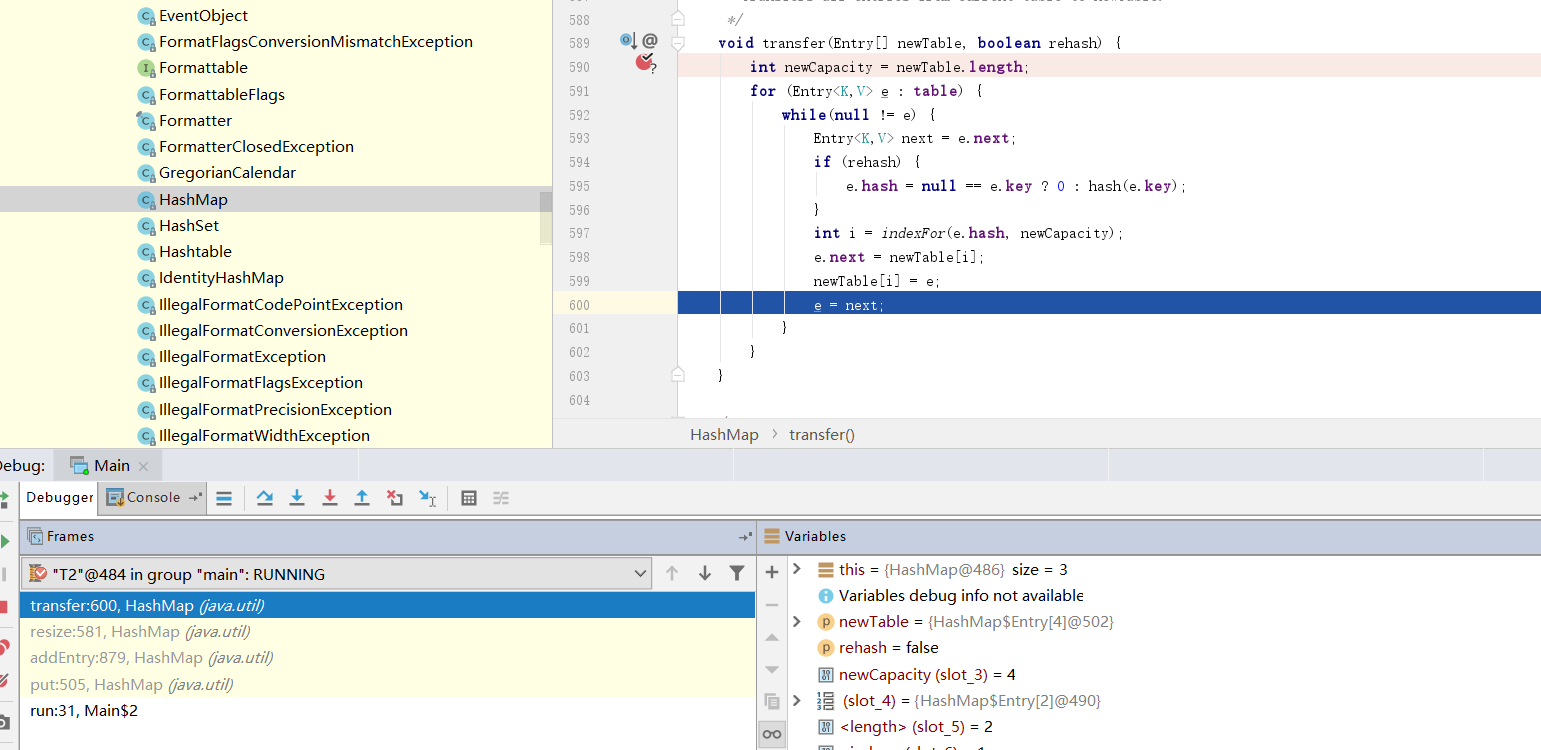
从控制台输出结果来看,控制台迟迟无法结束,说明扩容的操作迟迟无法完成,很明显线程1的扩容操作进入死循环,CPU100%问题由此印证。

jdk8版本源码解析
jdk8对HashMap底层数据结构做了调整,从原本的数组+链表转为数组+链表或红黑树的形式,这一点我们可以从put源码实现细节了解到。
put源码会调用putVal,计算key的hash值并将key和value传入。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}putVal的代码虽然很长,但是粗略阅读不难看出它做的事情很简单,整体逻辑可以分为4大分支:
- 如果key算得的索引位置没有元素则直接插入
- 如果key算得的位置有元素且转为链表则遍历到链表末端将节点插入。
- 如果key算得的索引有元素,且这个索引位置已经是红黑树则按照调用红黑树的插入方法完成插入。
- 如果key以存在数组中则直接覆盖数组中的value。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node < K, V > [] tab;
Node < K, V > p;
int n, i;
if((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;
//如果数组对应的索引里面没有元素,则直接插入
if((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);
else {
Node < K, V > e;
K k;
if(p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p;
//如果数组有值且转成红黑树则调用插入红黑树节点的方法完成插入
else if(p instanceof TreeNode) e = ((TreeNode < K, V > ) p).putTreeVal(this, tab, hash, key, value);
else {
//如果数组有值是链表则遍历链表,将节点追加到末端
for(int binCount = 0;; ++binCount) {
if((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if(binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果key已存在则覆盖原有的value
if(e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break;
p = e;
}
}
if(e != null) { // existing mapping for key
V oldValue = e.value;
if(!onlyIfAbsent || oldValue == null) e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if(++size > threshold) resize();
afterNodeInsertion(evict);
return null;
}多线程覆盖问题
同样的我们观察一下代码,代入两个线程执行一下,不难得出这段代码有问题
//如果数组对应的索引里面没有元素,则直接插入
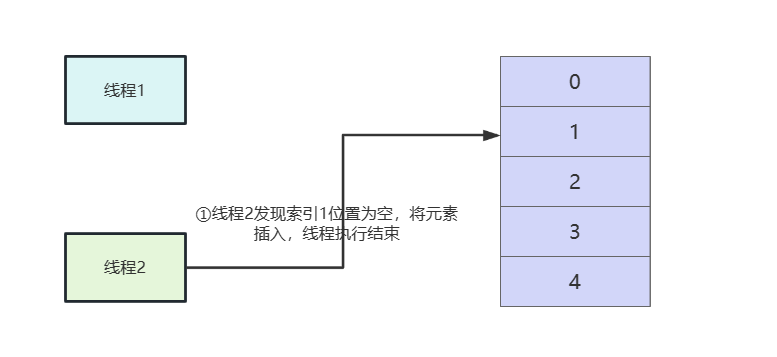
if((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);假如我们两个线程同时计算到i的位置为1:
- 线程1判断完if得知索引1位置为空后直接挂起。

- 线程2执行完这段代码逻辑。
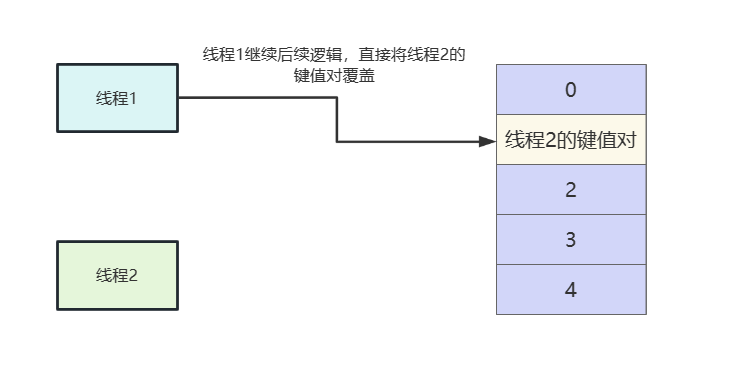
- 线程1被唤醒执行后续逻辑,这就会导致线程2的key被覆盖。
所以我们不妨写个代码印证这个问题,我们创建一个长度为2的map,用两个线程往map底层数组的同一个位置中插入键值对。两个线程分别起名为t1、t2,这样方便后续debug调试。
为了验证这个问题,笔者使用countDownLatch阻塞一下流程,只有两个线程都完成工作之后,才能执行后续输出逻辑。
private static HashMap < String, Long > map = new HashMap < > (2, 1.5 f);
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(2);
new Thread(() - > {
map.put("3", 3 L);
countDownLatch.countDown();
}, "t1").start();
new Thread(() - > {
map.put("5", 5 L);
countDownLatch.countDown();
}, "t2").start();
//等待上述线程执行完,继续执行后续输出逻辑
countDownLatch.await();
System.out.println(map.get("3"));
System.out.println(map.get("5"));
}然后在插入新节点的地方打个断点,debug模式设置为thread,条件设置为:
"t1".equals(Thread.currentThread().getName())||"t2".equals(Thread.currentThread().getName())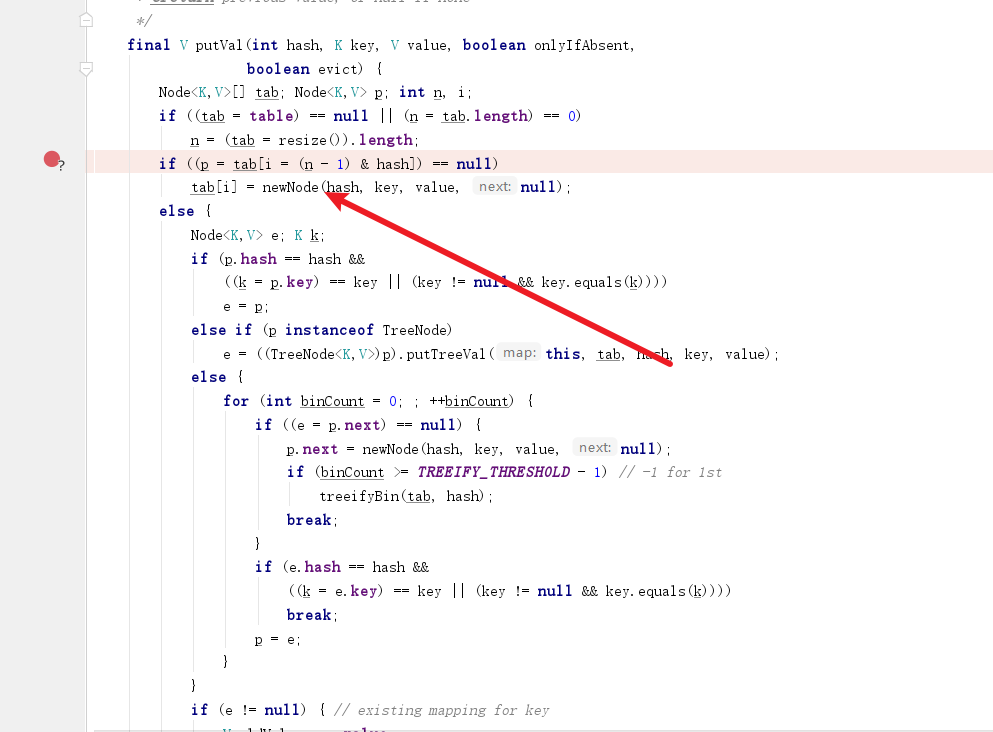
启动程序,我们在t1完成判断,正准备执行创建节点的操作时将线程切换为t2
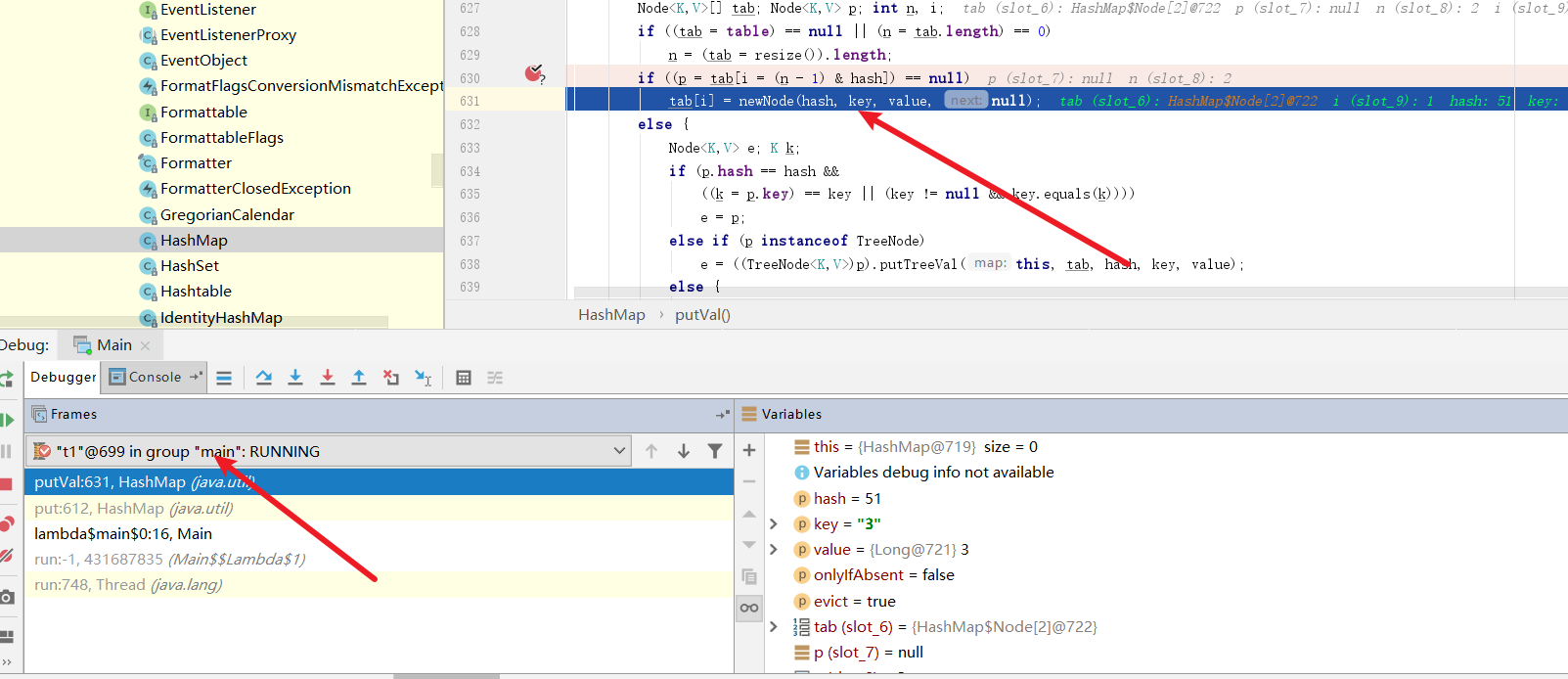
可以看到t2准备将(5,5)这个键值对插入到数组中,我们直接放行这个逻辑
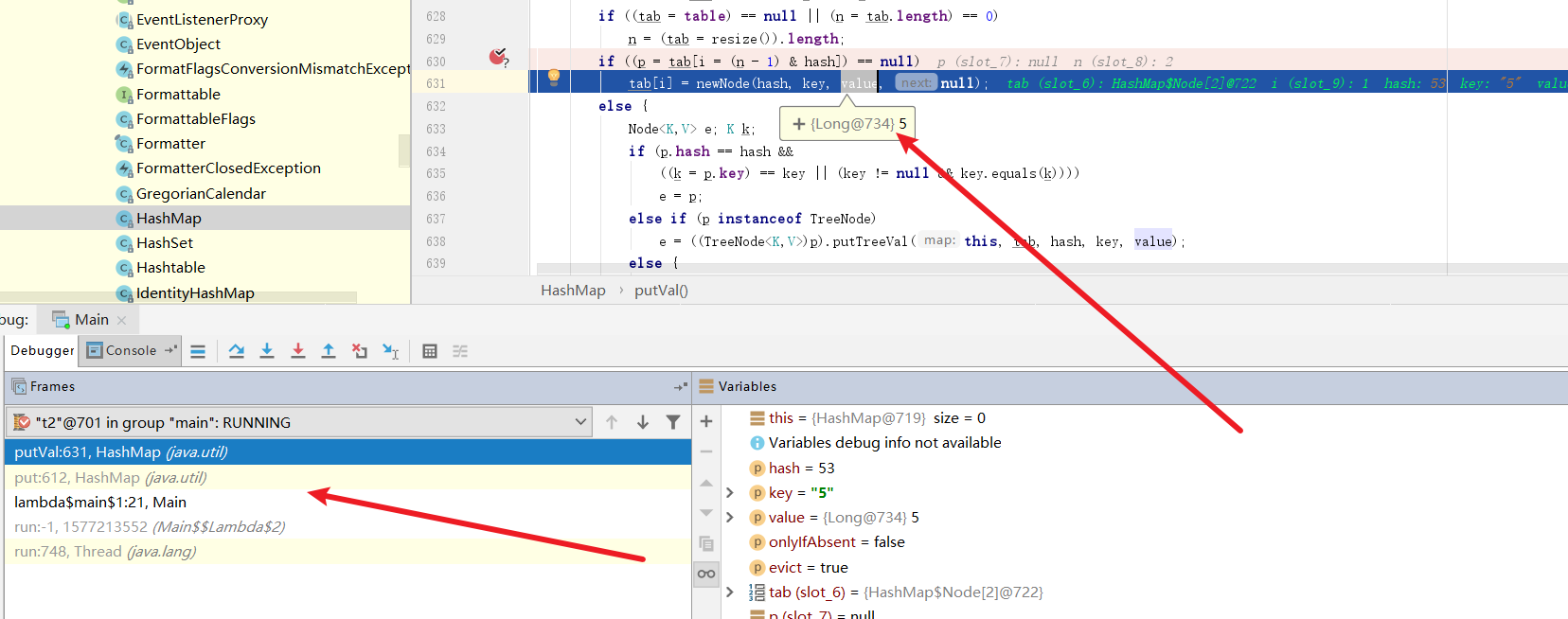
此时线程自动切回t1,我们放行断点,将(3,3)节点插入到数组中。此时,我们已经顺利将线程2的键值对覆盖了。
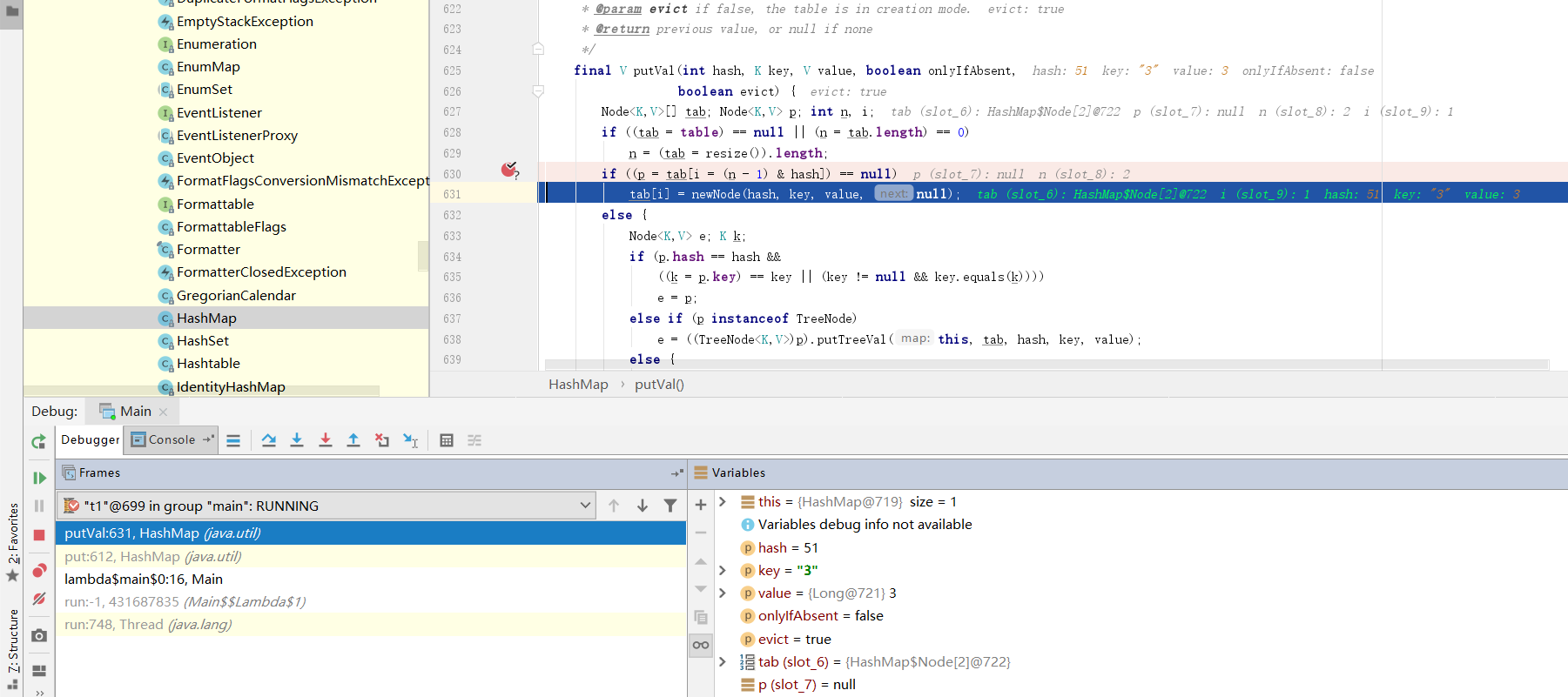
可以看到输出结果key为5的value为null,hashMap在多线程情况下的索引覆盖问题得以印证。
如何解决Map的线程安全问题
解决map线程安全问题有两种手段,一种是JDK自带的collections工具,另一种则是并发容器ConcurrentHashMap
为了演示冲突情况下的性能,我们使用不同的map执行100_0000次循环。
@Slf4j
public class MapTest {
@Test
public void mapTest() {
StopWatch stopWatch = new StopWatch();
stopWatch.start("synchronizedMap put");
Map<Object, Object> synchronizedMap = Collections.synchronizedMap(new HashMap<>());
IntStream.rangeClosed(0, 100_0000).parallel().forEach(i -> {
synchronizedMap.put(i, i);
});
stopWatch.stop();
stopWatch.start("concurrentHashMap put");
Map<Object, Object> concurrentHashMap = new ConcurrentHashMap<>();
IntStream.rangeClosed(0, 100_0000).parallel().forEach(i -> {
concurrentHashMap.put(i, i);
});
stopWatch.stop();
log.info(stopWatch.prettyPrint());
}
}从输出结果来看concurrentHashMap 在冲突频繁的情况下性能更加优异。
2023-03-14 20:29:25,669 INFO MapTest:37 - StopWatch '': running time (millis) = 1422
-----------------------------------------
ms % Task name
-----------------------------------------
00930 065% synchronizedMap put
00492 035% concurrentHashMap put原因很简单synchronizedMap的put方法,每次操作都会上锁,这意味着无论要插入的键值对在数组哪个位置,执行插入操作前都必须先得到操作map的锁,锁的粒度非常大。
public V put(K key, V value) {
synchronized(mutex) {
return m.put(key, value);
}
}反观concurrentHashMap 的synchronized 锁的仅仅只是数组中某个索引位置,相比前者粒度会小很多
final V putVal(K key, V value, boolean onlyIfAbsent) {
if(key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for(Node < K, V > [] tab = table;;) {
Node < K, V > f;
int n, i, fh;
if(tab == null || (n = tab.length) == 0) tab = initTable();
//获取当前键值对要存放的位置f
else if((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if(casTabAt(tab, i, null, new Node < K, V > (hash, key, value, null))) break; // no lock when adding to empty bin
} else if((fh = f.hash) == MOVED) tab = helpTransfer(tab, f);
else {
V oldVal = null;
//只要获得索引i位置的锁的即可
synchronized(f) {
if(tabAt(tab, i) == f) {
if(fh >= 0) {
binCount = 1;
for(Node < K, V > e = f;; ++binCount) {
K ek;
if(e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
oldVal = e.val;
if(!onlyIfAbsent) e.val = value;
break;
}
Node < K, V > pred = e;
if((e = e.next) == null) {
pred.next = new Node < K, V > (hash, key, value, null);
break;
}
}
} else if(f instanceof TreeBin) {
Node < K, V > p;
binCount = 2;
if((p = ((TreeBin < K, V > ) f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if(!onlyIfAbsent) p.val = value;
}
}
}
}
if(binCount != 0) {
if(binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i);
if(oldVal != null) return oldVal;
break;
}
}
}
addCount(1 L, binCount);
return null;
}ConcurrentHashMap使用注意事项
非原子化操作
使用ConcurrentHashMap存放键值对,并不一定意味着所有存的操作都是线程安全的。对于非原子化操作仍然是存在线程安全问题
如下所示,我们的代码首先会得到一个含有900的元素的ConcurrentHashMap,然后开10个线程去查看map中还差多少个键值对够1000个,缺多少补多少。
//线程数
private static int THREAD_COUNT = 10;
//数据项的大小
private static int ITEM_COUNT = 1000;
//返回一个size大小的ConcurrentHashMap
private ConcurrentHashMap < String, Object > getData(int size) {
return LongStream.rangeClosed(1, size).parallel().boxed().collect(Collectors.toConcurrentMap(i - > UUID.randomUUID().toString(), Function.identity(), (o1, o2) - > o1, ConcurrentHashMap::new));
}@
GetMapping("wrong")
public String wrong() throws InterruptedException {
//900个元素的ConcurrentHashMap
ConcurrentHashMap < String, Object > map = getData(ITEM_COUNT - 100);
log.info("init size:{}", map.size());
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
forkJoinPool.execute(() - > {
IntStream.rangeClosed(1, 10).parallel().forEach(i - > {
//判断当前map缺多少个元素就够1000个,缺多少补多少
int gap = ITEM_COUNT - map.size();
log.info("{} the gap:{}", Thread.currentThread().getName(), gap);
map.putAll(getData(gap));
});
});
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
log.info("finish size:{}", map.size());
return "ok";
}从输出结果可以看出,ConcurrentHashMap只能保存put的时候是线程安全,但无法保证put意外的操作线程安全,这段代码计算ConcurrentHashMap还缺多少键值对的操作很可能出现多个线程得到相同的差值,结果补入相同大小的元素,导致ConcurrentHashMap多存放键值对的情况。
2023-03-14 20:52:52,471 INFO ConcurrentHashMapMisuseController:44 - init size:900
2023-03-14 20:52:52,473 INFO ConcurrentHashMapMisuseController:51 - ForkJoinPool-1-worker-9 the gap:100
2023-03-14 20:52:52,473 INFO ConcurrentHashMapMisuseController:51 - ForkJoinPool-1-worker-2 the gap:100
2023-03-14 20:52:52,474 INFO ConcurrentHashMapMisuseController:51 - ForkJoinPool-1-worker-6 the gap:100
2023-03-14 20:52:52,474 INFO ConcurrentHashMapMisuseController:51 - ForkJoinPool-1-worker-4 the gap:100
2023-03-14 20:52:52,474 INFO ConcurrentHashMapMisuseController:51 - ForkJoinPool-1-worker-13 the gap:100
2023-03-14 20:52:52,474 INFO ConcurrentHashMapMisuseController:51 - ForkJoinPool-1-worker-11 the gap:100
2023-03-14 20:52:52,474 INFO ConcurrentHashMapMisuseController:51 - ForkJoinPool-1-worker-9 the gap:0
2023-03-14 20:52:52,474 INFO ConcurrentHashMapMisuseController:51 - ForkJoinPool-1-worker-15 the gap:0
2023-03-14 20:52:52,474 INFO ConcurrentHashMapMisuseController:51 - ForkJoinPool-1-worker-10 the gap:-100
2023-03-14 20:52:52,474 INFO ConcurrentHashMapMisuseController:51 - ForkJoinPool-1-worker-9 the gap:0
2023-03-14 20:52:52,476 INFO ConcurrentHashMapMisuseController:60 - finish size:1500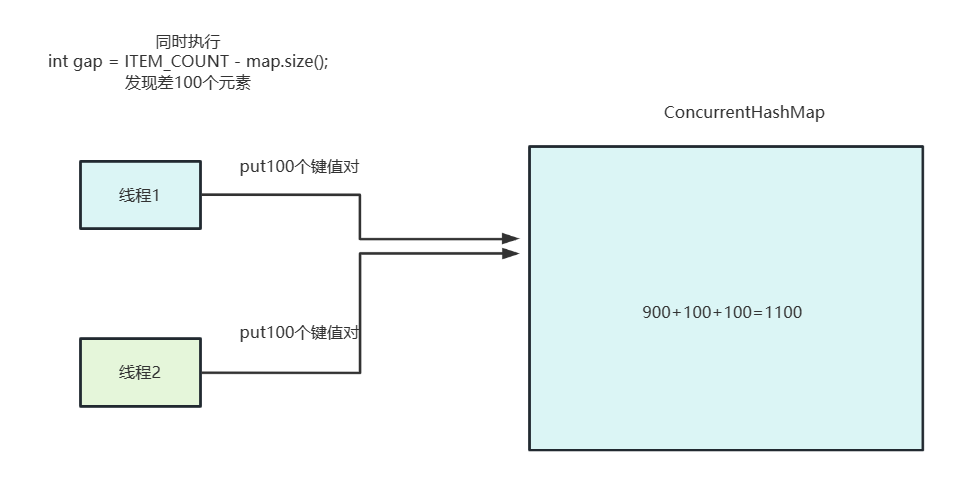
解决方式也很简单,将查询缺少个数和put操作原子化,说的通俗一点就是对查和插两个操作上一把锁确保多线程互斥即可
@GetMapping("right")
public String right() throws InterruptedException {
ConcurrentHashMap < String, Object > map = getData(ITEM_COUNT - 100);
log.info("init size:{}", map.size());
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
forkJoinPool.execute(() - > {
IntStream.rangeClosed(1, 10).parallel().forEach(i - > {
synchronized(map) {
int gap = ITEM_COUNT - map.size();
log.info("{} the gap:{}", Thread.currentThread().getName(), gap);
map.putAll(getData(gap));
}
});
});
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
log.info("finish size:{}", map.size());
return "ok";
}可以看到输出结果正常了。
2023-03-14 20:59:56,730 INFO ConcurrentHashMapMisuseController:69 - init size:900
2023-03-14 20:59:56,732 INFO ConcurrentHashMapMisuseController:76 - ForkJoinPool-2-worker-9 the gap:100
2023-03-14 20:59:56,733 INFO ConcurrentHashMapMisuseController:76 - ForkJoinPool-2-worker-4 the gap:0
2023-03-14 20:59:56,734 INFO ConcurrentHashMapMisuseController:76 - ForkJoinPool-2-worker-8 the gap:0
2023-03-14 20:59:56,734 INFO ConcurrentHashMapMisuseController:76 - ForkJoinPool-2-worker-9 the gap:0
2023-03-14 20:59:56,734 INFO ConcurrentHashMapMisuseController:76 - ForkJoinPool-2-worker-1 the gap:0
2023-03-14 20:59:56,734 INFO ConcurrentHashMapMisuseController:76 - ForkJoinPool-2-worker-15 the gap:0
2023-03-14 20:59:56,734 INFO ConcurrentHashMapMisuseController:76 - ForkJoinPool-2-worker-2 the gap:0
2023-03-14 20:59:56,734 INFO ConcurrentHashMapMisuseController:76 - ForkJoinPool-2-worker-6 the gap:0
2023-03-14 20:59:56,735 INFO ConcurrentHashMapMisuseController:76 - ForkJoinPool-2-worker-11 the gap:0
2023-03-14 20:59:56,735 INFO ConcurrentHashMapMisuseController:76 - ForkJoinPool-2-worker-13 the gap:0
2023-03-14 20:59:56,737 INFO ConcurrentHashMapMisuseController:87 - finish size:1000合理使用API发挥ConcurrentHashMap最大性能
我们会循环1000w次,在这1000w次随机生成10以内的数字,以10以内数字为key,出现次数为value存放到ConcurrentHashMap中。
你可能会写出这样一段代码
//map中的项数
private static int ITEM_COUNT = 10;
//线程数
private static int THREAD_COUNT = 10;
//循环次数
private static int LOOP_COUNT = 1000 _0000;
private Map < String, Long > normaluse() throws InterruptedException {
Map < String, Long > map = new ConcurrentHashMap < > (ITEM_COUNT);
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
LongStream.rangeClosed(1, LOOP_COUNT).parallel().forEach(i - > {
String key = "item" + ThreadLocalRandom.current().nextInt(ITEM_COUNT);
synchronized(map) {
if(map.containsKey(key)) {
map.put(key, map.get(key) + 1);
} else {
map.put(key, 1 L);
}
}
});
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
return map;
}实际上判断key是否存在,若不存在则初始化这个key的操作,在ConcurrentHashMap中已经提供好了这样的API。 我们通过computeIfAbsent进行判断key是否存在,若不存在则初始化的原子操作,注意此时的value是一个Long类型的累加器,这个LongAdder是一个线程安全的累加器,通过LongAdder的increment方法确保多线程情况下,这一点我们可以在LongAdder的注释中得知。
LongAdders can be used with a {@link
* java.util.concurrent.ConcurrentHashMap} to maintain a scalable
* frequency map (a form of histogram or multiset). For example, to
* add a count to a {@code ConcurrentHashMap<String,LongAdder> freqs},
* initializing if not already present, you can use {@code
* freqs.computeIfAbsent(k -> new LongAdder()).increment();}大概意思是说LongAdder可以用于统计频率等场景,使用的代码方式为:
ConcurrentHashMap<String,LongAdder> freqs
freqs.computeIfAbsent(k -> new LongAdder()).increment();所以我们改进后的代码如下
private Map < String, Long > gooduse() throws InterruptedException {
Map < String, LongAdder > map = new ConcurrentHashMap < > (ITEM_COUNT);
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
LongStream.rangeClosed(1, LOOP_COUNT).parallel().forEach(i - > {
String key = "item" + ThreadLocalRandom.current().nextInt(ITEM_COUNT);
map.computeIfAbsent(key, k - > new LongAdder()).increment();
});
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
return map.entrySet().stream().collect(Collectors.toMap(e - > e.getKey(), e - > e.getValue().longValue()));
}完成后我们不妨对这段代码进行性能压测
@GetMapping("good")
public String good() throws InterruptedException {
StopWatch stopWatch = new StopWatch();
stopWatch.start("normaluse");
Map < String, Long > normaluse = normaluse();
stopWatch.stop();
Assert.isTrue(normaluse.size() == ITEM_COUNT, "normaluse size error");
Assert.isTrue(normaluse.entrySet().stream().mapToLong(i - > i.getValue().longValue()).reduce(0, Long::sum) == LOOP_COUNT, "normaluse count error");
stopWatch.start("gooduse");
Map < String, Long > gooduse = gooduse();
stopWatch.stop();
Assert.isTrue(gooduse.size() == ITEM_COUNT, "gooduse size error");
Assert.isTrue(gooduse.entrySet().stream().mapToLong(i - > i.getValue().longValue()).reduce(0, Long::sum) == LOOP_COUNT, "gooduse count error");
log.info(stopWatch.prettyPrint());
return "ok";
}很明显后者的性能要优于前者,那么原因是什么呢?
-----------------------------------------
ms % Task name
-----------------------------------------
03458 080% normaluse
00871 020% gooduse从ConcurrentHashMap的computeIfAbsent中不难看出,其底层实现"若key不存在则初始化"是通过ReservationNode+CAS实现的,相比于上一段代码那种非原子化的操作性能自然高出不少。

ArrayList线程安全问题
问题重现以原因
我们使用并行流在多线程情况下往list中插入100w个元素。
@Test
public void listTest() {
StopWatch stopWatch = new StopWatch();
List < Object > list = new ArrayList < > ();
IntStream.rangeClosed(1, 100 _0000).parallel().forEach(i - > {
list.add(i);
});
Assert.assertEquals(100 _0000, list.size());
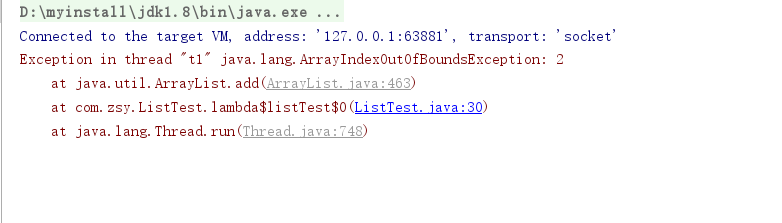
}从输出结果来看,list确实发生了线程安全问题。
java.lang.AssertionError:
Expected :1000000
Actual :377628
<Click to see difference>我们不妨看看arrayList的add方法,它的逻辑为:
- 判断当前数组空间是否可以容纳新元素,若不够则创建一个新数组,并将旧数组的元素全部转移到新数组中
- 将元素e追加到数组末尾
public boolean add(E e) {
//确定当前数组空间是否足够,若不足则扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
//将元素添加到末尾
elementData[size++] = e;
return true;
}所以如果我们两个线程同时得到线程空间足够,然后两个线程分别执行插入逻辑。
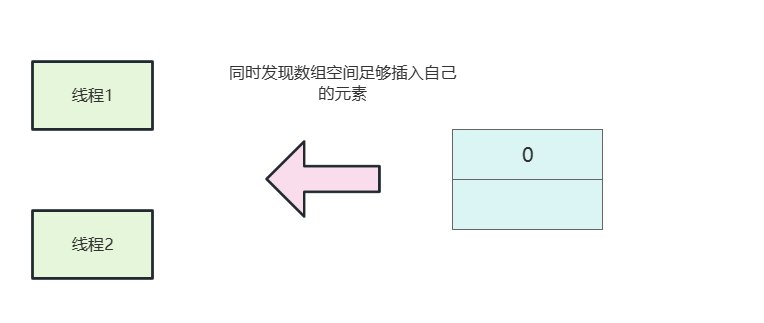
线程1执行插入,size++变为2。
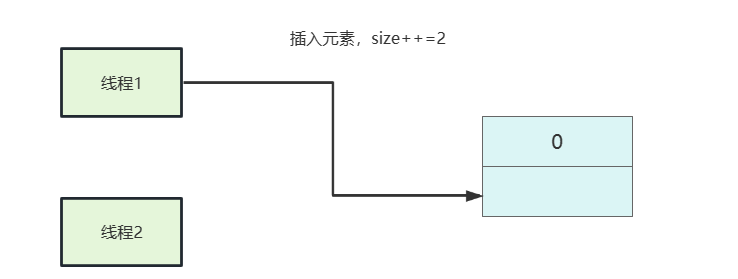
线程2出现索引越界
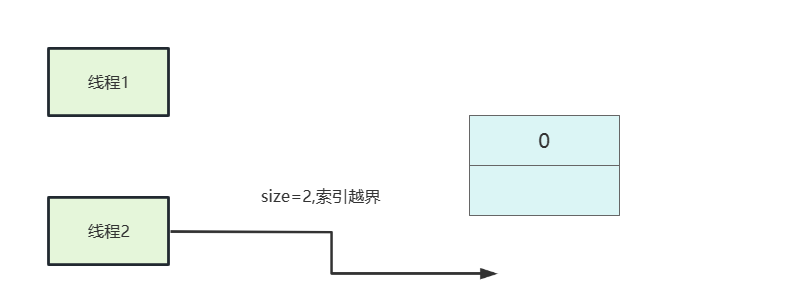
我们同样可以写一段简单的代码就能轻易重现这个问题
@Test
public void listTest() throws InterruptedException {
ArrayList < Object > list = new ArrayList < > (2);
CountDownLatch countDownLatch = new CountDownLatch(2);
list.add(0);
new Thread(() - > {
list.add(1);
countDownLatch.countDown();
}, "t1").start();
new Thread(() - > {
list.add(2);
countDownLatch.countDown();
}, "t2").start();
countDownLatch.await();
System.out.println(list.toString());
}我们的add方法上打一个断点,并设置条件为t1和t2两个线程
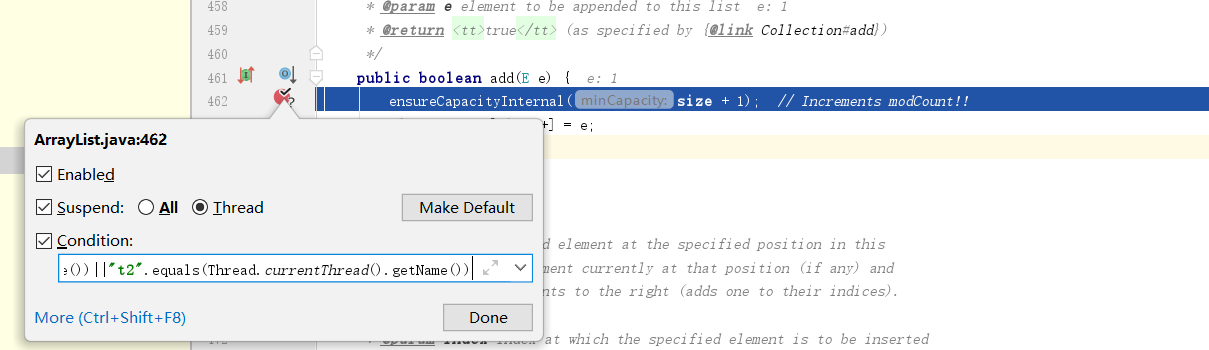
在t1线程正准备插入元素时,切换线程到t2
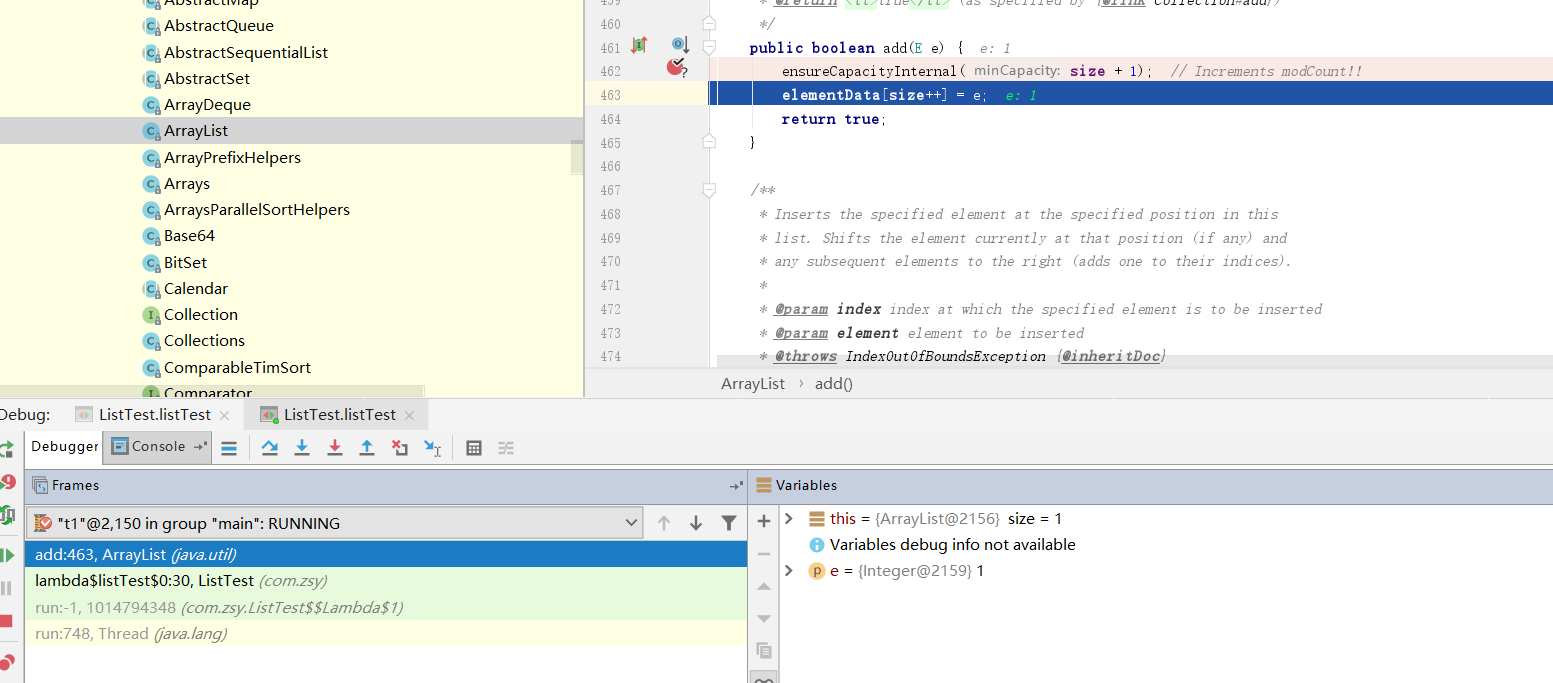
然后直接将t2线程放行,回到t1线程放行后续操作。问题得以重现
解决ArrayList线程安全问题的两个思路
在此回到这段代码,解决这段代码线程安全问题的方式有两种
@Test
public void listTest() {
StopWatch stopWatch = new StopWatch();
List < Object > list = new ArrayList < > ();
IntStream.rangeClosed(1, 100 _0000).parallel().forEach(i - > {
list.add(i);
});
Assert.assertEquals(100 _0000, list.size());
}第一种是使用synchronizedList
@Test
public void listTest() {
List < Object > list = Collections.synchronizedList(new ArrayList < > ());
IntStream.rangeClosed(1, 100 _0000).parallel().forEach(i - > {
list.add(i);
});
Assert.assertEquals(100 _0000, list.size());
}第二种则是使用CopyOnWriteArrayList
@Test
public void listTest() {
List < Object > list = new CopyOnWriteArrayList < > ();
IntStream.rangeClosed(1, 100 _0000).parallel().forEach(i - > {
list.add(i);
});
Assert.assertEquals(100 _0000, list.size());
}synchronizedList和CopyOnWriteArrayList区别
虽然两者都可以保证并发操作的线程安全,但我们还是需要注意两者使用场景上的区别:
synchronizedList保证多线程操作安全的原理很简单,每次执行插入或者读取操作前上锁。
public E get(int index) {
synchronized(mutex) {
return list.get(index);
}
}
public void add(int index, E element) {
synchronized(mutex) {
list.add(index, element);
}
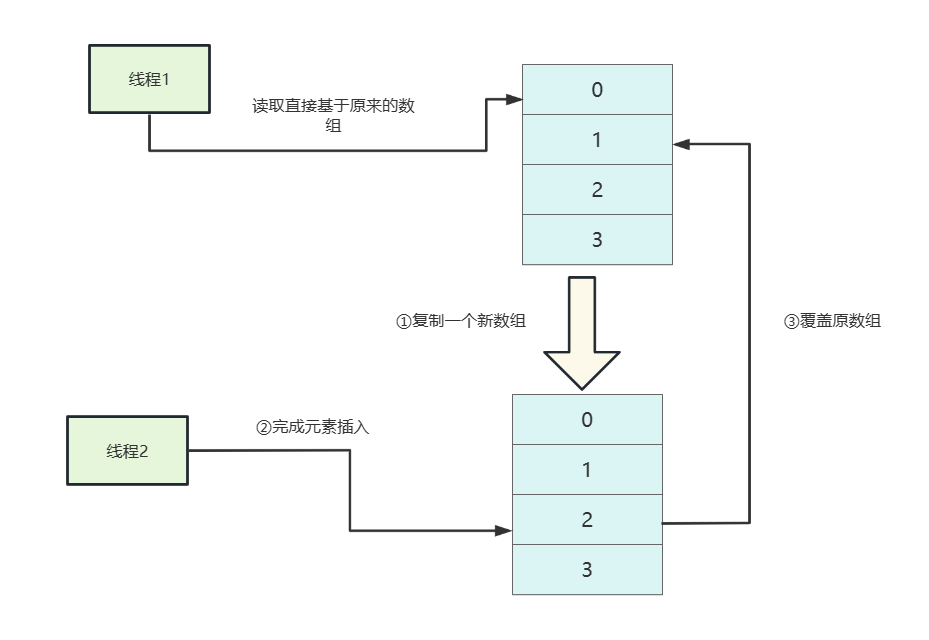
}CopyOnWriteArrayList意味写时复制,从源码中不难看出它保证线程安全的方式开销非常大:
- 获得写锁。
- 复制一个新数组newElements 。
- 在newElements 添加元素。
- 将数组修改为newElements。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
而对于读CopyOnWriteArrayList则非常简单,直接返回原数组的值。
private E get(Object[] a, int index) {
return(E) a[index];
}所以CopyOnWriteArrayList更适合与读多写少的场景。
对此我们对两者读写性能进行了一次压测,首先是写性能压测
@GetMapping("testWrite")
public Map testWrite() {
int loopCount = 10 _0000;
CopyOnWriteArrayList < Integer > copyOnWriteArrayList = new CopyOnWriteArrayList < > ();
List < Integer > synchronizedList = Collections.synchronizedList(new ArrayList < > ());
//使用copyOnWriteArrayList添加10w个数据
StopWatch stopWatch = new StopWatch();
stopWatch.start("copyOnWriteArrayList add");
IntStream.rangeClosed(1, loopCount).parallel().forEach(__ - > copyOnWriteArrayList.add(ThreadLocalRandom.current().nextInt(loopCount)));
stopWatch.stop();
//使用synchronizedList添加10w个数据
stopWatch.start("synchronizedList add");
IntStream.rangeClosed(1, loopCount).parallel().forEach(__ - > synchronizedList.add(ThreadLocalRandom.current().nextInt(loopCount)));
stopWatch.stop();
log.info(stopWatch.prettyPrint());
Map < String, Integer > result = new HashMap < > ();
result.put("copyOnWriteArrayList", copyOnWriteArrayList.size());
result.put("synchronizedList", synchronizedList.size());
return result;
}可以看出,高并发写的情况下synchronizedList 性能更加。
2023-03-15 00:16:14,532 INFO CopyOnWriteListMisuseController:39 - StopWatch '': running time (millis) = 5556
-----------------------------------------
ms % Task name
-----------------------------------------
05527 099% copyOnWriteArrayList add
00029 001% synchronizedList add读取性能压测代码
@GetMapping("testRead")
public Map testRead() {
int loopCount = 100 _0000;
CopyOnWriteArrayList < Integer > copyOnWriteArrayList = new CopyOnWriteArrayList < > ();
List < Integer > synchronizedList = Collections.synchronizedList(new ArrayList < > ());
//为两个list设置100_0000个元素
addAll(copyOnWriteArrayList);
addAll(synchronizedList);
//随机读取copyOnWriteArrayList中的元素
StopWatch stopWatch = new StopWatch();
stopWatch.start("copyOnWriteArrayList read");
IntStream.rangeClosed(0, loopCount).parallel().forEach(__ - > copyOnWriteArrayList.get(ThreadLocalRandom.current().nextInt(loopCount)));
stopWatch.stop();
//随机读取synchronizedList中的元素
stopWatch.start("synchronizedList read");
IntStream.rangeClosed(0, loopCount).parallel().forEach(__ - > synchronizedList.get(ThreadLocalRandom.current().nextInt(loopCount)));
stopWatch.stop();
log.info(stopWatch.prettyPrint());
Map < String, Integer > result = new HashMap < > ();
result.put("copyOnWriteArrayList", copyOnWriteArrayList.size());
result.put("synchronizedList", synchronizedList.size());
return result;
}
private void addAll(List < Integer > list) {
list.addAll(IntStream.rangeClosed(1, 100 _0000).parallel().boxed().collect(Collectors.toList()));
}而在高并发读的情况下synchronizedList 性能更加
2023-03-15 00:16:54,335 INFO CopyOnWriteListMisuseController:74 - StopWatch '': running time (millis) = 310
-----------------------------------------
ms % Task name
-----------------------------------------
00037 012% copyOnWriteArrayList read
00273 088% synchronizedList read小结
以上笔者对高并发容器的个人理解,总的来说读者必须掌握以下几点:
- 通过阅读源码了解容器工作机制,代入多线程绘图推算出可能存在的线程安全问题,并学会使用IDEA加以实践落地推算结果。
- 了解并发容器工作原理和所有API,确定在指定的场景可以正确使用并发容器保证线程安全和性能。
参考文献
为啥HashMap 桶中超过 8 个才转为红黑树(opens new window)
为什么说ArrayList是线程不安全的?(opens new window)
ConcurrentHashMap源码&底层数据结构分析(opens new window)
Java 业务开发常见错误 100 例(opens new window)
ConcurrentHashMap源码&底层数据结构分析(opens new window)
大厂常问的HashMap线程安全问题,看这一篇就够了!(opens new window)