 XfyCoding博客
XfyCoding博客Java线程池详解
为什么需要线程池
- 提高响应速度:通过线程池创建一系列线程,使用时直接通过线程池获取,不再需要手动创建线程,响应速度大大提高。
- 降低资源消耗:由于线程池被池化管理了,我们无需为了某些功能去手动创建和销毁线程,资源消耗自然降低。
- 便于管理和监控:因为我们的工作线程都来自于线程池中所以对于线程的监控和管理自然方便了许多。
线程池使用入门
接下来我们展示了一个非常简单的demo,创建一个含有3个线程的线程,提交3个任务到线程池中,让线程池中的线程池执行。 完成后通过shutdown停止线程池,线程池收到通知后会将手头的任务都执行完,再将线程池停止,所以笔者这里使用isTerminated判断线程池是否完全停止了。只有状态为terminated才能说明线程池关闭了,结束循环,退出方法。
@Test
void contextLoads() {
//创建含有3个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(3);
//提交3个任务到线程池中
for(int i = 0; i < 3; i++) {
final int taskNo = i;
threadPool.execute(() - > {
logger.info("执行任务{}", taskNo);
});
}
//关闭线程池
threadPool.shutdown();
//如果线程池还没达到Terminated状态,说明线程池中还有任务没有执行完,则继续循环等待线程池执行完任务
while(!threadPool.isTerminated()) {}
}输出结果
2023-03-21 23:01:16.198 INFO 40176 --- [pool-4-thread-1] .j.JavaCommonMistakes100ApplicationTests : 执行任务0
2023-03-21 23:01:16.198 INFO 40176 --- [pool-4-thread-2] .j.JavaCommonMistakes100ApplicationTests : 执行任务1
2023-03-21 23:01:16.225 INFO 40176 --- [pool-4-thread-3] .j.JavaCommonMistakes100ApplicationTests : 执行任务2线程池详解
线程池核心参数详解
我们上文通过Executors框架创建了线程池,我们不如源码可以看到,它底层是通过ThreadPoolExecutor完成线程池的创建,我们不妨步入查看一下ThreadPoolExecutor的几个参数
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0 L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue < Runnable > ());
}可以看到ThreadPoolExecutor的构造方法包含下面几个参数,它们分别是:
1. corePoolSize:核心线程数,即时空闲也会保留在线程池中的线程。
2. maximumPoolSize:线程池允许创建的最大线程数,例如配置为10,那么线程池中最大的线程数就为10。
3. keepAliveTime:核心线程数以外的线程的生存时间,例如corePoolSize为2,maximumPoolSize为5,假如我们线程池中有5个线程,核心线程以外有3个,这3个线程如果在keepAliveTime的时间内没有被用到就会被回收。
4. unit:keepAliveTime的时间单位。
5. workQueue:当核心线程都在忙碌时,任务都会先放到队列中。
6. threadFactory:线程工厂,用户可以通过这个参数指定创建线程的线程工厂。
7. handler:当线程池无法接受新的任务时,就会根据这个参数做出拒绝策略,默认拒绝策略是直接抛异常。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
//略
}线程池的工作流程
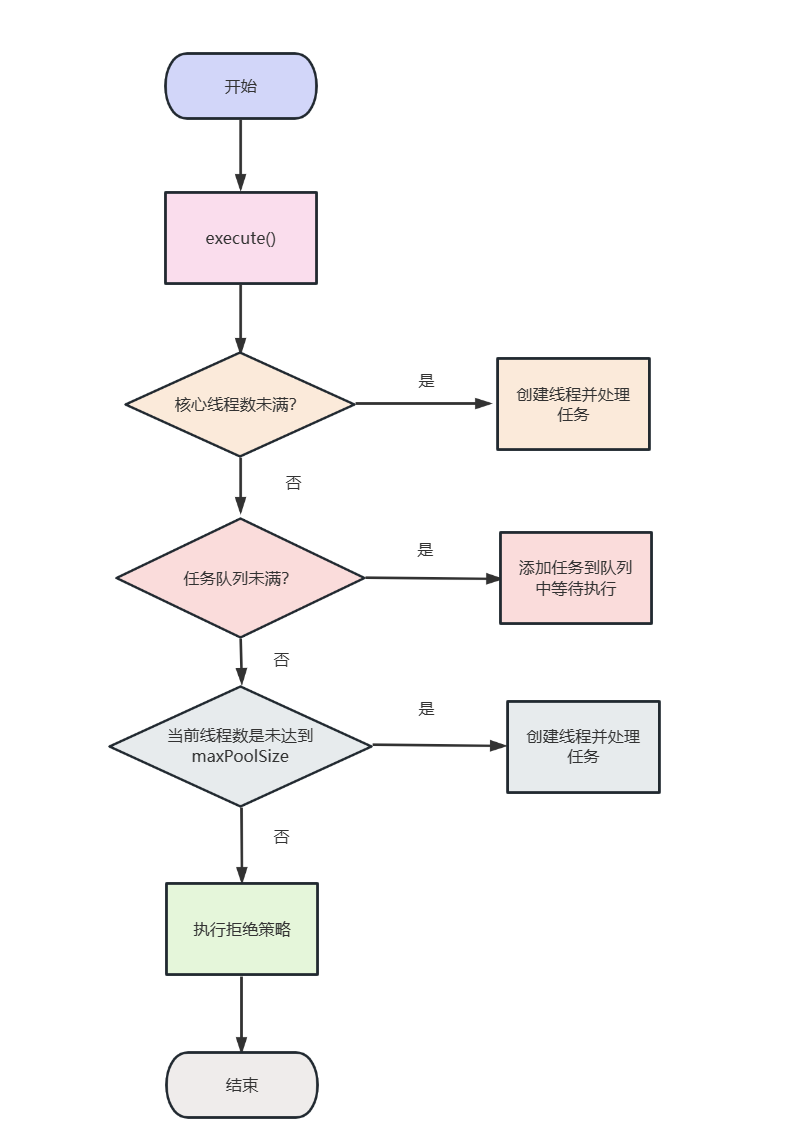
要想了解线程池的工作流程,我们不妨步入execute查看任务提交后的工作逻辑,可以看到它们的核心步骤很简单:
- 如果工作的线程小于核心线程数,则调用
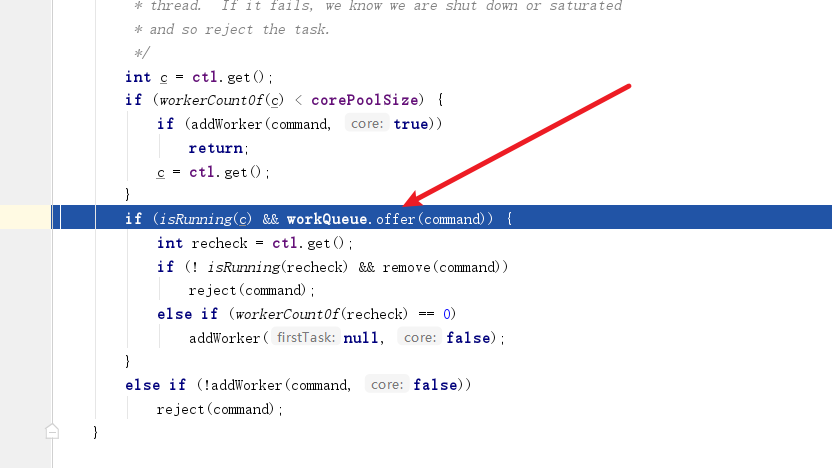
addWorker创建线程并执行我们传入的任务。 - 如果核心线程都在工作,则调用
workQueue.offer(command)将我们提交的任务放到队列中。 - 如果队列也无法容纳任务时,则继续创建线程并用这些线程处理新进来的任务。
- 此时,当线程数达到maximumPoolSize时,说明已经无法容纳任务了,则调用
reject(command)按照拒绝策略处理任务。
public void execute(Runnable command) {
if(command == null) throw new NullPointerException();
int c = ctl.get();
if(workerCountOf(c) < corePoolSize) {
if(addWorker(command, true)) return;
c = ctl.get();
}
if(isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if(!isRunning(recheck) && remove(command)) reject(command);
else if(workerCountOf(recheck) == 0) addWorker(null, false);
} else if(!addWorker(command, false)) reject(command);
}为了更好的讲解线程池,笔者写了下面这样一段代码,我们创建一个线程池,然后开启thread的debug模式来调试这段代码。
/**
* 线程池工作流程
*/
@Test
void workflow() {
//创建含有3个线程的线程池
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 3, 1, TimeUnit.HOURS, new ArrayBlockingQueue < > (1), new ThreadFactoryBuilder().setNameFormat("threadPool-%d").get());
//提交3个任务到线程池中
for(int i = 0; i < 15; i++) {
final int taskNo = i;
threadPool.execute(() - > {
logger.info("执行任务{}开始", taskNo);
try {
TimeUnit.HOURS.sleep(1);
} catch(InterruptedException e) {
e.printStackTrace();
}
logger.info("执行任务{}结束", taskNo);
});
}
//关闭线程池
threadPool.shutdown();
//如果线程池还没达到Terminated状态,说明线程池中还有任务没有执行完,则继续循环等待线程池执行完任务
while(!threadPool.isTerminated()) {}
}开启thread的debug模式,便于调试线程。
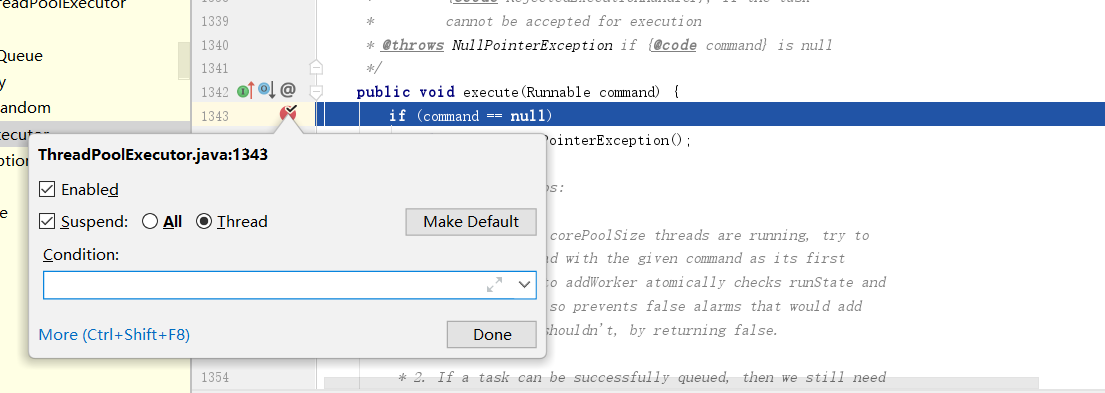
首先任务0进来,发现此时工作线程小于核心线程数,直接调用addWorker创建线程并处理掉传入的任务。

然后任务1进来,此时线程数为1,小于核心线程数2,再创建一个线程并处理进来的任务2。
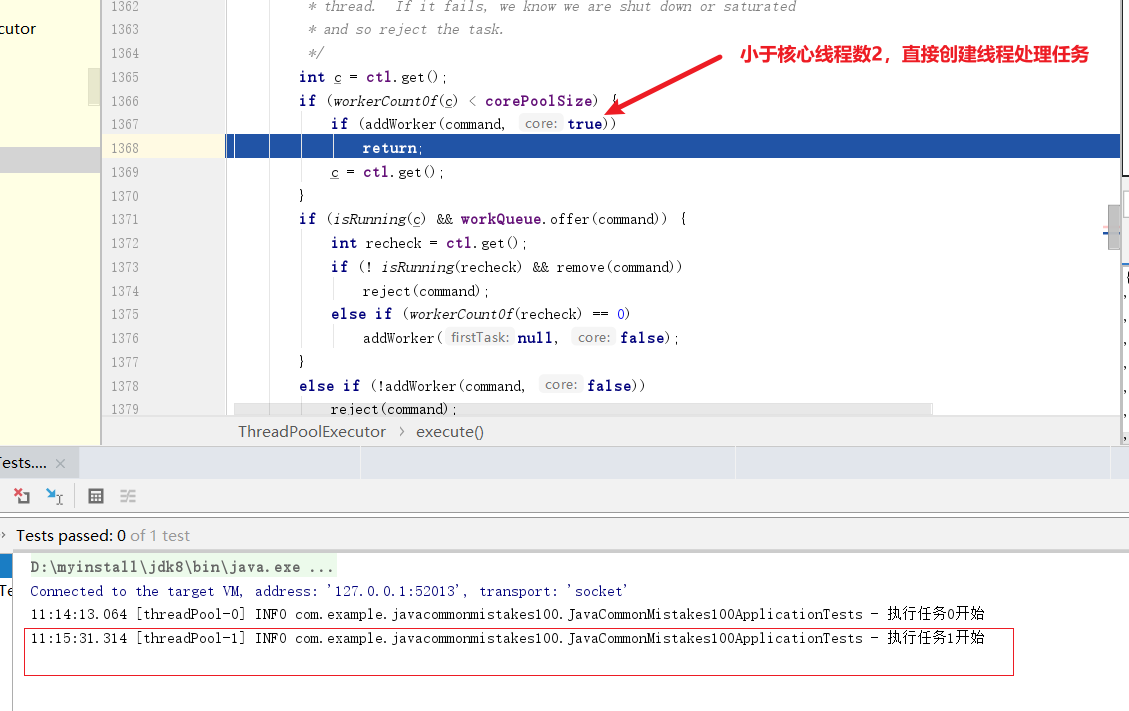
任务2进入,发现核心线程都在工作,所以将任务提交到队列中直接返回。
任务3进来,由于队列容量为1,所以队列无法容纳新任务了,线程池赶紧开启临时工作线程处理任务。
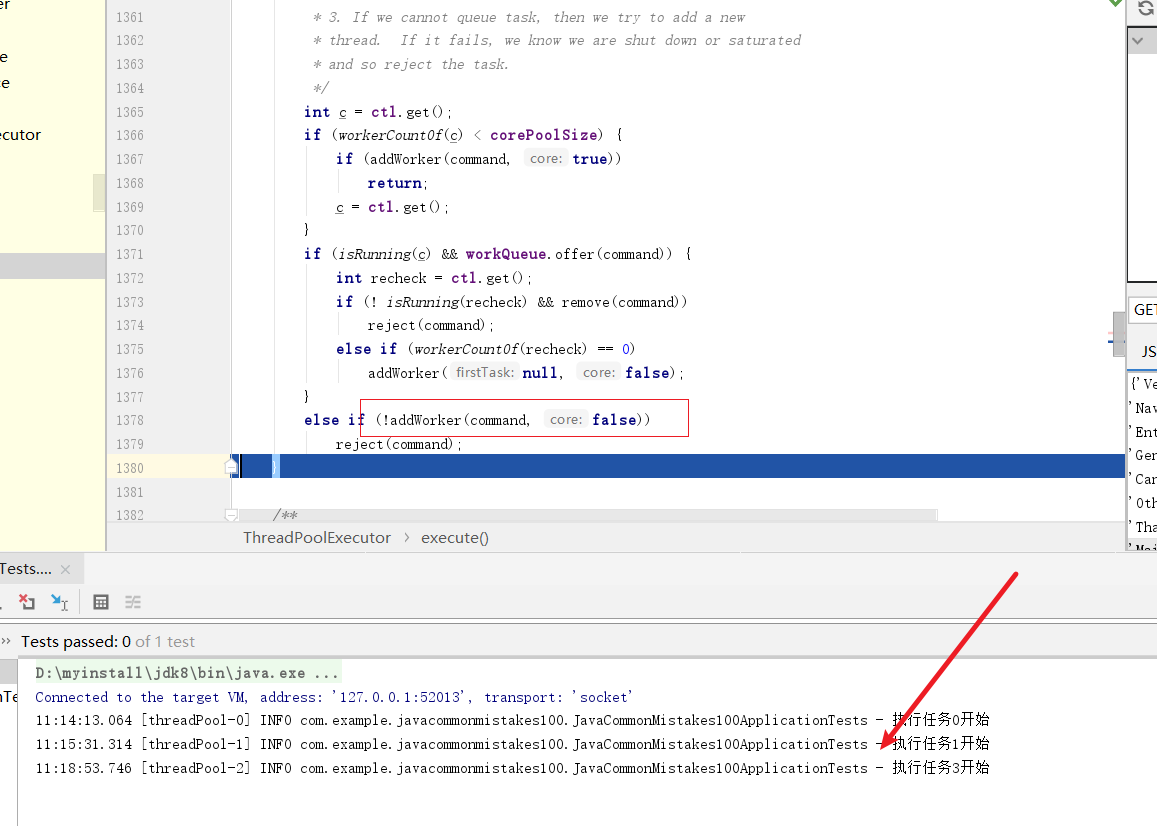
任务4进来,发现线程数已经开到最大线程数了,addWorker失败,直接走拒绝策略,抛出异常。

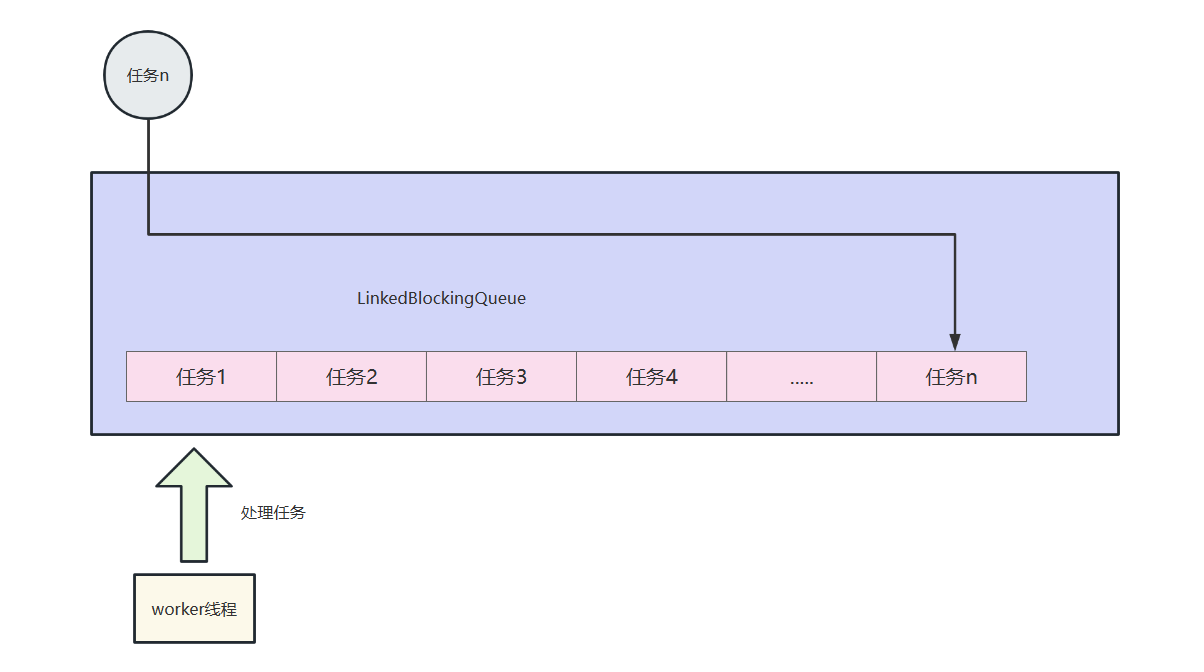
最后我们用一张流程图总结一下线程池的核心工作流程。
线程池队列
对于线程池的队列,我们可以通过点击线程池参数BlockingQueue来查看具体实现类。
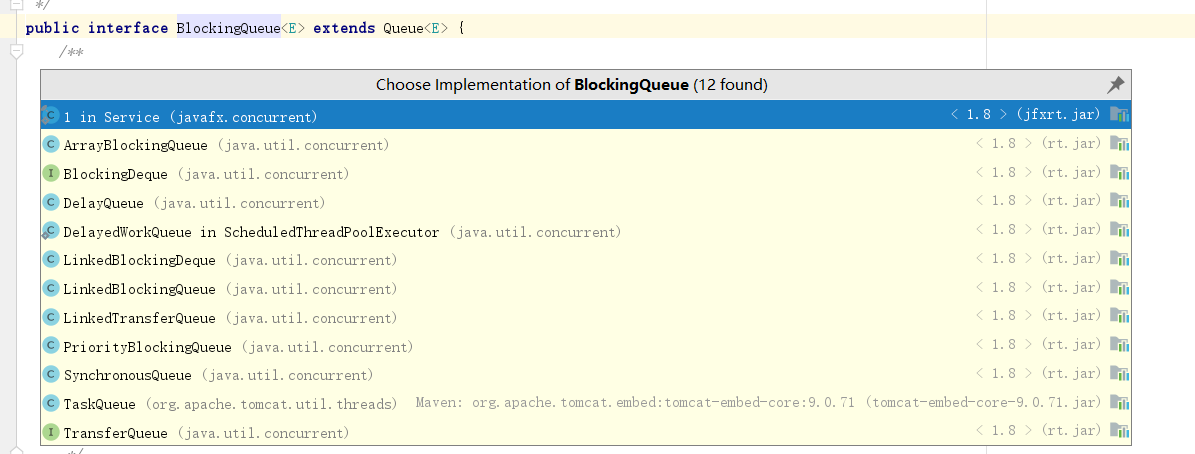
可以看到线程池的可以这几种实现:
- ArrayBlockingQueue:由数组构成的有界阻塞队列,按照FIFO的方式对元素进行排序。
- LinkedBlockingQueue:由链表构成的队列,按照FIFO的对元素进行排序,任务默认的大小为Integer.MAX_VALUE,当然我们也可以设置链表容量大小。
- DelayQueue:延迟队列,提交的任务会按照执行时间进行从小到大的方式进行排序,否则就按照插入到队列的先后顺序进行排列。
- PriorityBlockingQueue:优先队列,按照优先级进行排序,是一个具备优先级的无界队列。
- SynchronousQueue:同步队列,是一个不能存储元素的阻塞队列,每一次向队列中插入数据必须等到另一个线程移除操作,否则插入操作会一直处于阻塞状态。
线程池的几种状态
从源码中我们可以看到这么几个变量,它们就是线程池的几种状态。
//RUNNING 说明线程正处于运行状态,正在处理任务和接受新的任务进来
private static final int RUNNING = -1 << COUNT_BITS;
//说明线程收到关闭的通知了,继续处理手头任务,但不接受新任务
private static final int SHUTDOWN = 0 << COUNT_BITS;
//STOP说明线程停止了不处理任务也不接受任务,即时队列中有任务,我们也会将其打断。
private static final int STOP = 1 << COUNT_BITS;
//表明所有任务都已经停止,记录的任务数量为0
private static final int TIDYING = 2 << COUNT_BITS;
//线程池完全停止了
private static final int TERMINATED = 3 << COUNT_BITS;线程池的几种拒绝策略
同样的我们通过源码找到这几个实现类
AbortPolicy:从源码中可以看出,这个拒绝策略在无法容纳新任务的时候直接抛出异常,这种策略是线程池默认的拒绝策略。
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() {}
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() + " rejected from " + e.toString());
}
}CallerRunsPolicy:从源码中可以看出,当线程池无法容纳新任务的时,会直接将当前任务交给调用者执行。
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() {}
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if(!e.isShutdown()) {
r.run();
}
}
}DiscardOldestPolicy :顾名思义,当线程池无法最新任务时,会将队首的任务丢弃,将新任务存入。
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() {}
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if(!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}DiscardPolicy:从源码中可以看出这个策略什么也不做,相当于直接将当前任务丢弃。
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() {}
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {}
}线程两种任务提交方式
我们还是通过源码来了解两者的差异,首先是execute,上文已经详细说明了,当任务提交到线程池中时直接按照流程执行即可,处理完成后是没有返回值的。
public void execute(Runnable command) {
if(command == null) throw new NullPointerException();
int c = ctl.get();
if(workerCountOf(c) < corePoolSize) {
if(addWorker(command, true)) return;
c = ctl.get();
}
if(isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if(!isRunning(recheck) && remove(command)) reject(command);
else if(workerCountOf(recheck) == 0) addWorker(null, false);
} else if(!addWorker(command, false)) reject(command);
}submit说白了就是套一个execute,它会将传进来的任务封装成RunnableFuture,然后将Future返回出去,调用者可以通过get方法获取返回结果。
public < T > Future < T > submit(Callable < T > task) {
if(task == null) throw new NullPointerException();
RunnableFuture < T > ftask = newTaskFor(task);
execute(ftask);
return ftask;
}使用示例
@Test
void baseUse() throws ExecutionException, InterruptedException {
//创建含有3个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(3);
//提交3个任务到线程池中
for(int i = 0; i < 3; i++) {
final int taskNo = i;
Future < Integer > future = threadPool.submit(() - > {
logger.info("执行任务{}", taskNo);
return 1;
});
logger.info("处理结果:{}", future.get());
}
//关闭线程池
threadPool.shutdown();
//如果线程池还没达到Terminated状态,说明线程池中还有任务没有执行完,则继续循环等待线程池执行完任务
while(!threadPool.isTerminated()) {}
}输出结果
00:24:41.204 [pool-1-thread-1] INFO com.example.javacommonmistakes100.JavaCommonMistakes100ApplicationTests - 执行任务0
00:24:41.208 [main] INFO com.example.javacommonmistakes100.JavaCommonMistakes100ApplicationTests - 处理结果:1
00:24:41.209 [pool-1-thread-2] INFO com.example.javacommonmistakes100.JavaCommonMistakes100ApplicationTests - 执行任务1
00:24:41.209 [main] INFO com.example.javacommonmistakes100.JavaCommonMistakes100ApplicationTests - 处理结果:1
00:24:41.209 [pool-1-thread-3] INFO com.example.javacommonmistakes100.JavaCommonMistakes100ApplicationTests - 执行任务2
00:24:41.209 [main] INFO com.example.javacommonmistakes100.JavaCommonMistakes100ApplicationTests - 处理结果:1线程池的关闭方式
线程池的停止方式有两种:
- shutdown:笔者上述代码示例用的都是这种方式,使用这个方法之后,我们无法提交新的任务进来,线程池会继续工作,将手头的任务执行完再停止。
- shutdownNow:这种停止方式就比较粗暴了,线程池会直接将手头的任务都强行停止,且不接受新任务进来,线程停止立即生效。
线程池使用注意事项
避免使用Executors的newFixedThreadPool
接下来我们来看看日常使用线程池时一些错误示例,为了更好的看到线程池的变化,我们编写这样一个定时任务去监控线程池的变化。
/**
* 打印线程池情况
*
* @param threadPool
*/
private void printStats(ThreadPoolExecutor threadPool) {
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() - > {
log.info("=========================");
log.info("Pool Size:{}", threadPool.getPoolSize());
log.info("Active Threads:{}", threadPool.getActiveCount());
log.info("Number of Tasks Completed: {}", threadPool.getCompletedTaskCount());
log.info("Number of Tasks in Queue:{}", threadPool.getQueue().size());
log.info("=========================");
}, 0, 1, TimeUnit.SECONDS);
}先来看看这样一段代码,我们循环1e次,每次创建这样一个任务:生成一串大字符串,休眠一小时后打印输出。
public void oom1() {
ThreadPoolExecutor threadPool = (ThreadPoolExecutor) Executors.newFixedThreadPool(1);
printStats(threadPool);
for(int i = 0; i < 1 _0000_0000; i++) {
threadPool.submit(() - > {
String payload = IntStream.rangeClosed(1, 100 _0000).mapToObj(__ - > "a").collect(Collectors.joining("")) + UUID.randomUUID().toString();
try {
TimeUnit.HOURS.sleep(1);
} catch(InterruptedException e) {
e.printStackTrace();
}
log.info(payload);
});
}
threadPool.shutdown();
while(!threadPool.isTerminated()) {}
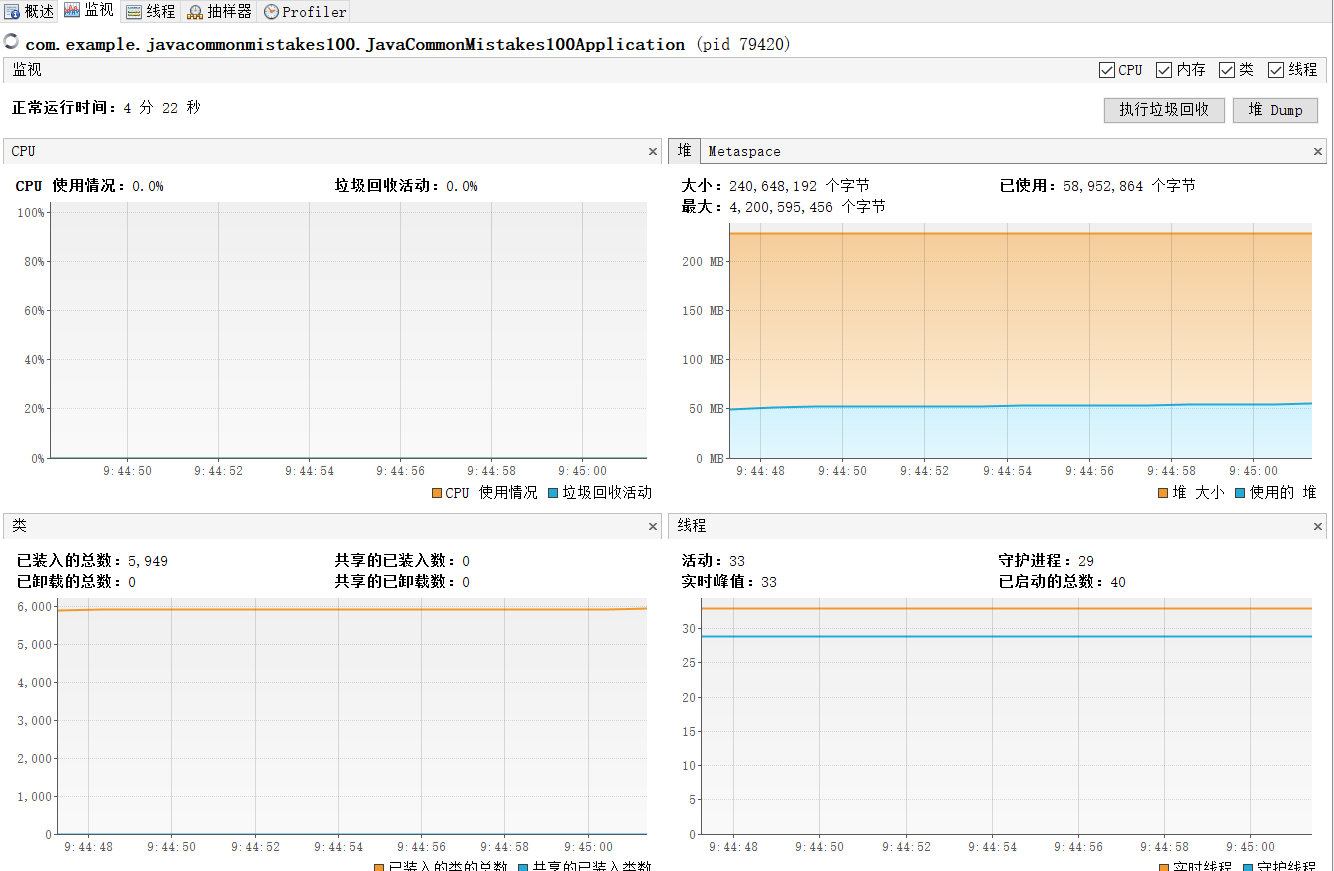
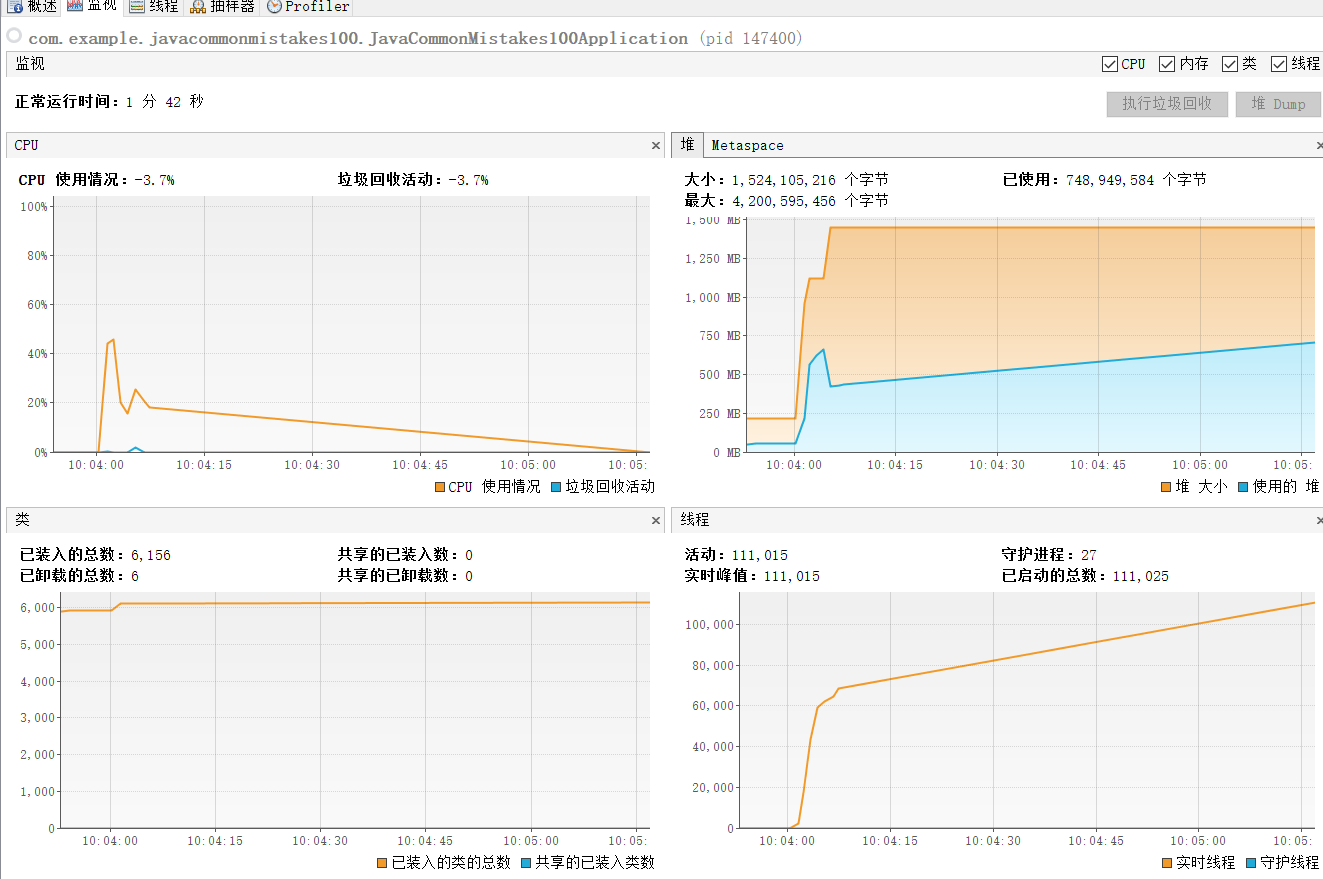
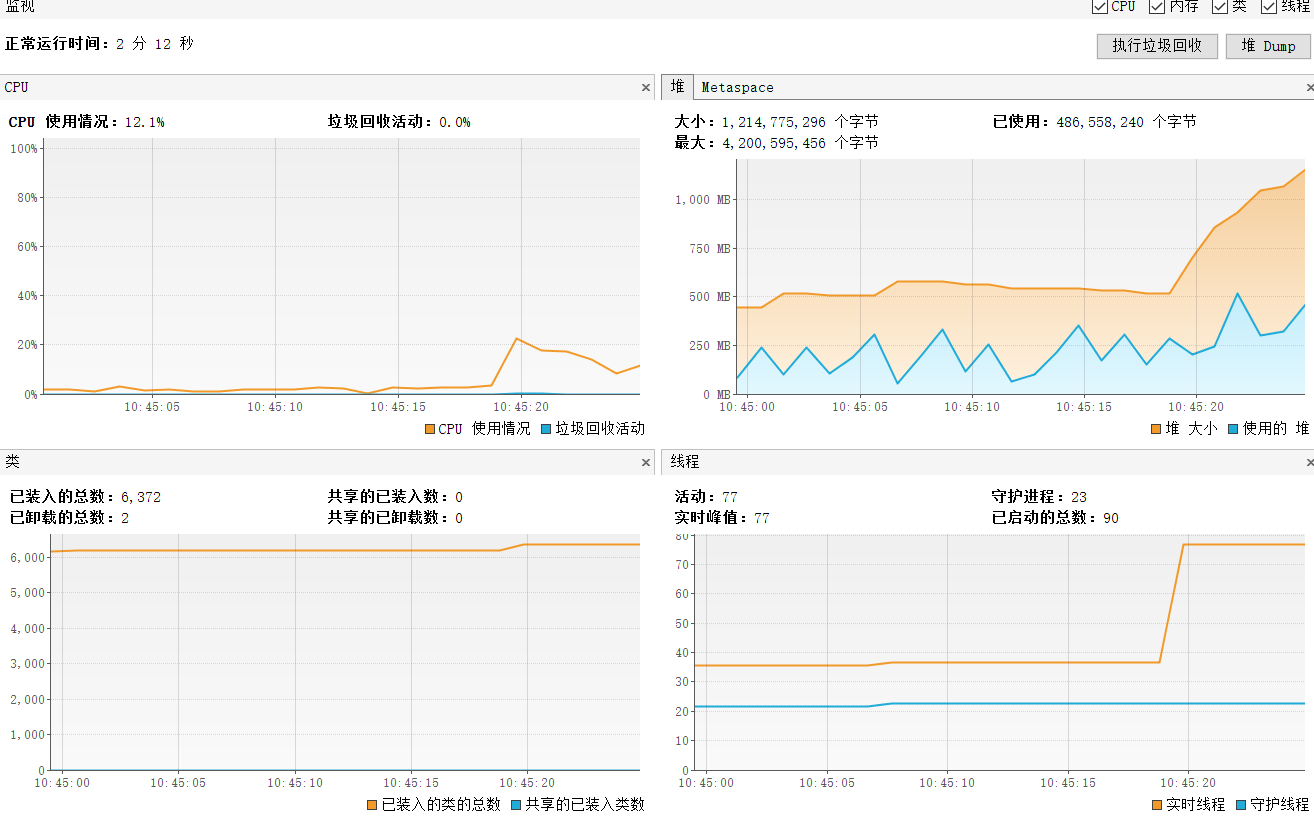
}项目启动后使用jvisualvm监控项目的变化。
可以看到此时CPU使用情况,堆区、还有线程数使用情况都是正常的。
然后我们对刚刚的接口发起请求
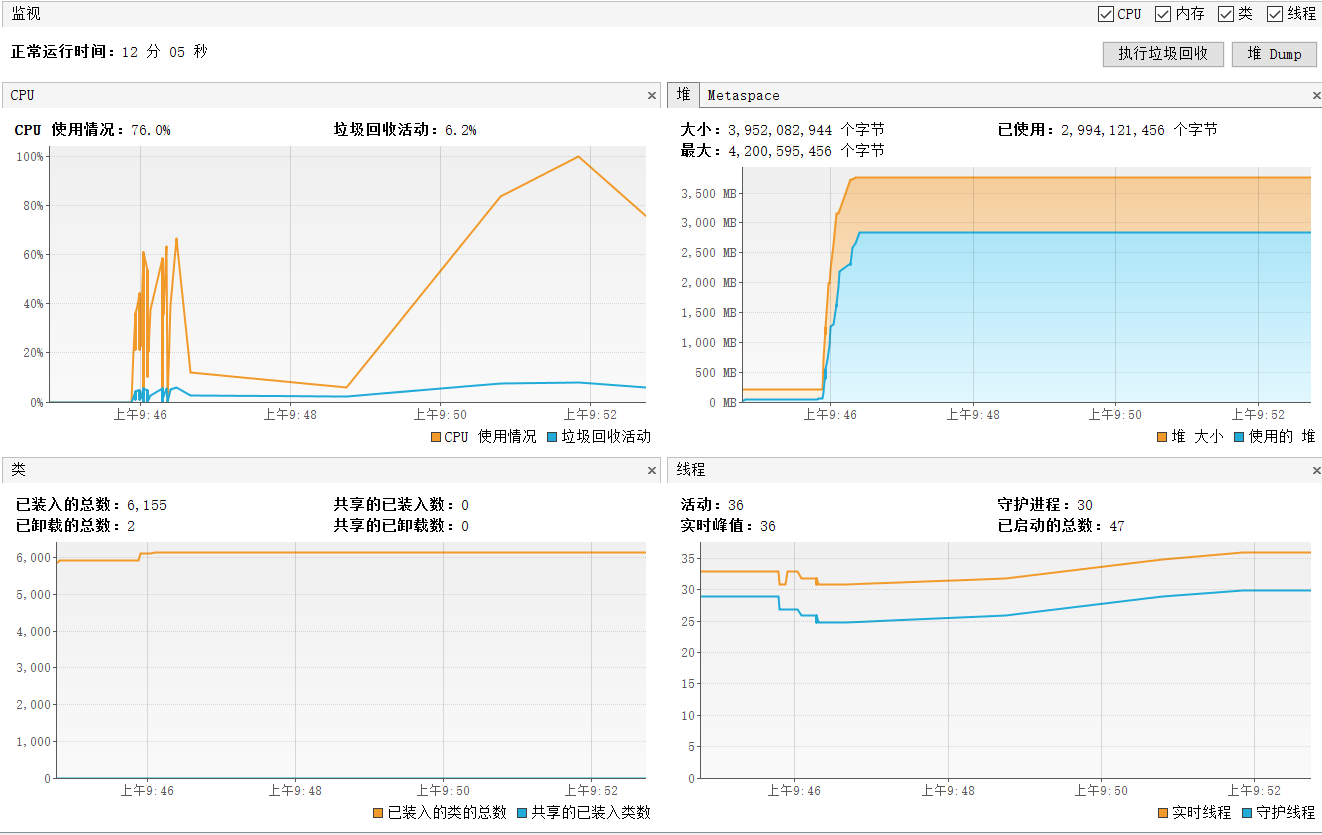
curl http://localhost:8080/threadpooloom/oom1我们先来看看控制台输出,可以看到线程数没有增加,而队列的任务却不断累积。

看看jvisualvm,此时堆区内存不断增加,尽管发生了几次GC,还是没有回收到足够的空间。最终引发OOM问题。
我们通过源码来观察一下newFixedThreadPool的特征,可以看到它的核心线程数和最大线程数都是传进来的值,这意味着无论多少个任务进来,线程数都是nThreads。如果我们没有足够的线程去执行的任务的话,任务就会堆到LinkedBlockingQueue中,从源码中我们也能看出,LinkedBlockingQueue是无界队列。 所以我们我们日常应该避免使用newFixedThreadPool。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0 L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue < Runnable > ());
}
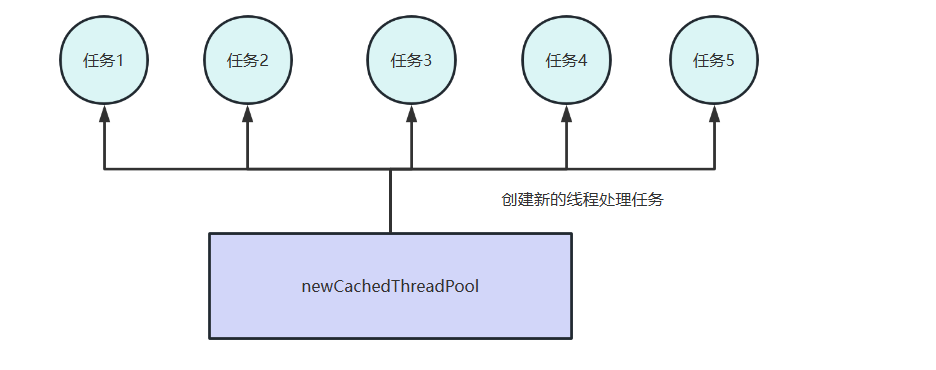
避免使用Executors的newCachedThreadPool
再来看看第二段代码,同样的任务提交到newCachedThreadPool中,我们看看会发生什么。
public void oom2() {
ThreadPoolExecutor threadPool = (ThreadPoolExecutor) Executors.newCachedThreadPool();
printStats(threadPool);
for(int i = 0; i < 1 _0000_0000; i++) {
threadPool.submit(() - > {
String payload = IntStream.rangeClosed(1, 100 _0000).mapToObj(__ - > "b").collect(Collectors.joining("")) + UUID.randomUUID().toString();
try {
TimeUnit.HOURS.sleep(1);
} catch(InterruptedException e) {
e.printStackTrace();
}
log.info(payload);
});
}
threadPool.shutdown();
while(!threadPool.isTerminated()) {}
}先来看看控制台,可以看到线程数正在不断的飙升。

从jvisualvm也能看出堆区和线程数也在不断飙升,最终导致OOM。
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (malloc) failed to allocate 32744 bytes for ChunkPool::allocate
# An error report file with more information is saved as:
# F:\github\java-common-mistakes-100\hs_err_pid147400.log我们来看看newCachedThreadPool源码,可以看到这个线程池核心线程数初始为0,最大线程数为Integer.MAX_VALUE,而队列使用的是SynchronousQueue,所以这个队列等于不会存储任何任务。
这就意味着我们每次提交一个任务没有线程处理的话,线程池就会创建一个新的线程去处理这个任务,1s内没有线程使用就将其销毁。
我们的连续1e次循环提交任务就会导致创建1e个线程,最终导致线程数飙升,进而引发OOM问题。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60 L, TimeUnit.SECONDS, new SynchronousQueue < Runnable > ());
}
确保你创建线程池的方式线程可以被复用
我们监控发现某段时间线程会不断飙升,然后急速下降,然后急速上升
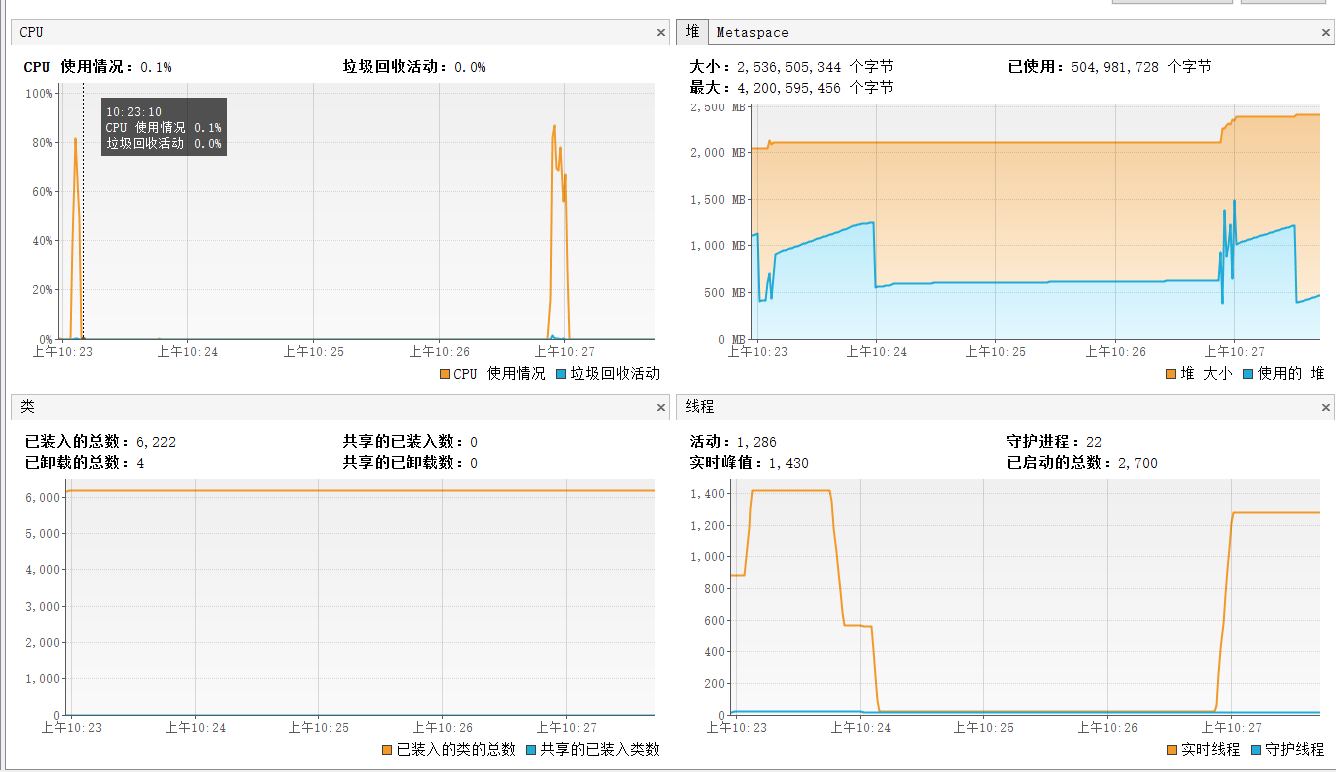
然后我们在线程的栈帧中看到SynchronousQueue,大概率有人使用newCachedThreadPool。
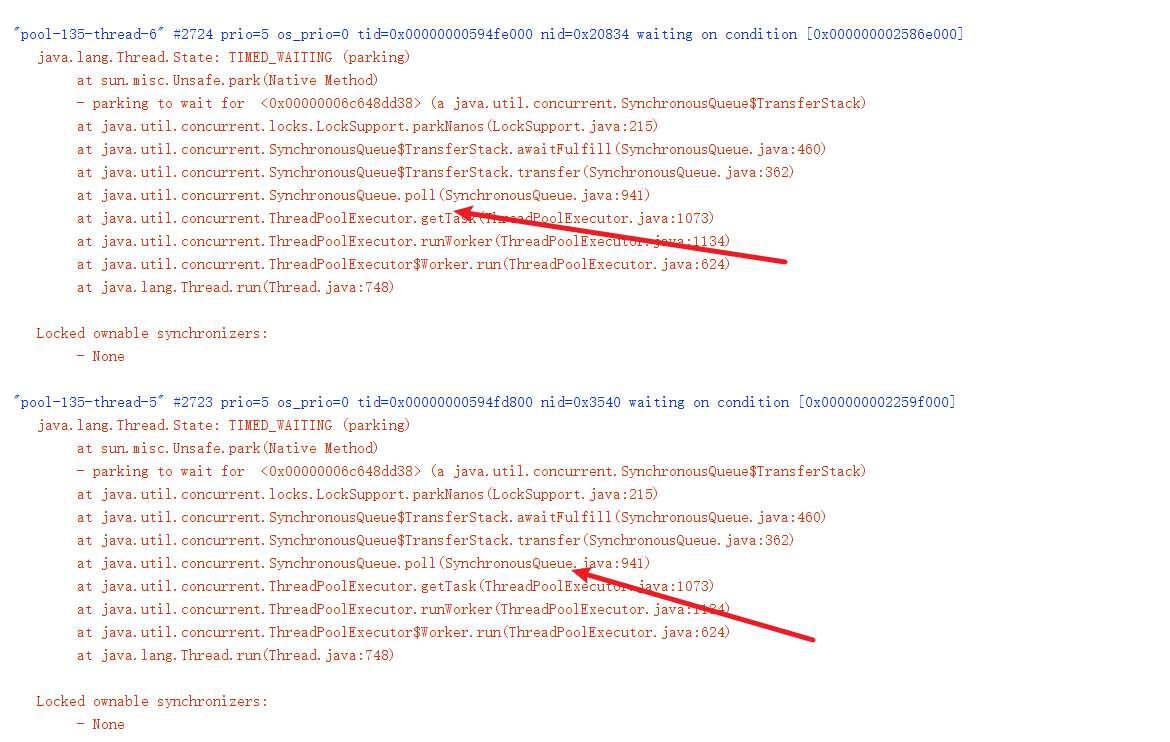
最终通过全局搜索看到这样一段代码,可以看到这个工具类每次请求就会创建一个newCachedThreadPool给用户使用。
static class ThreadPoolHelper {
public static ThreadPoolExecutor getThreadPool() {
return(ThreadPoolExecutor) Executors.newCachedThreadPool();
}
}我们在定位到调用出,真想明了了,原来每一次请求都会创建一个newCachedThreadPool处理大量的任务,由于newCachedThreadPool回收时间为1s,所以线程使用完之后立刻就被回收了。
public String wrong() {
ThreadPoolExecutor threadPool = ThreadPoolHelper.getThreadPool();
IntStream.rangeClosed(1, 20).forEach(i - > {
threadPool.execute(() - > {
String payload = IntStream.rangeClosed(1, 1000000).mapToObj(__ - > "a").collect(Collectors.joining("")) + UUID.randomUUID().toString();
try {
TimeUnit.SECONDS.sleep(1);
} catch(InterruptedException e) {}
log.debug(payload);
});
});
return "ok";
}解决方式也很简单,我们按需调整线程池参数,将线程池作为静态变量全局复用即可。
static class ThreadPoolHelper {
private static ThreadPoolExecutor threadPool = new ThreadPoolExecutor(10, 50, 2, TimeUnit.SECONDS, new ArrayBlockingQueue < > (1000), new ThreadFactoryBuilder().setNameFormat("demo-threadpool-%d").get());
public static ThreadPoolExecutor getRightThreadPool() {
return threadPool;
}
}从监控来看线程数正常多了。
仔细斟酌线程混用策略
我们使用线程池来处理一些异步任务,每个任务耗时10ms左右。
public int wrong() throws ExecutionException, InterruptedException {
return threadPool.submit(calcTask()).get();
}
private Callable < Integer > calcTask() {
return() - > {
log.info("执行异步任务");
TimeUnit.MILLISECONDS.sleep(10);
return 1;
};
}压测的时候发现性能很差,处理时间最长要283ms。
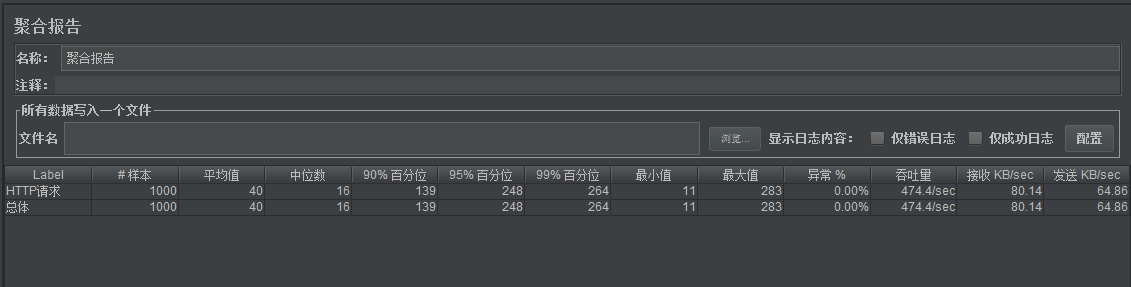
步入线程池发现,线程池的配置如下,只有2个线程和50个队列。
private ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 2, 1, TimeUnit.HOURS, new ArrayBlockingQueue < > (50), new ThreadFactoryBuilder().setNameFormat("batchfileprocess-threadpool-%d").get(), new ThreadPoolExecutor.CallerRunsPolicy());查看调用发现,原来后台有一个处理字符串并将内容写入到文本文件的操作,综合来看相当于一个计算型任务,由于这个任务不是很经常出现,所以开发者就设置两个线程,并且为了让任务能够正确完成,拒绝策略也是使用CallerRunsPolicy,让多出来的任务用调用者线程来执行。
@PostConstruct
public void init() {
printStats(threadPool);
new Thread(() - > {
String payload = IntStream.rangeClosed(1, 100 _0000).mapToObj(__ - > "a").collect(Collectors.joining(""));
while(true) {
threadPool.execute(() - > {
try {
Files.write(Paths.get("demo.txt"), Collections.singletonList(LocalTime.now().toString() + ":" + payload), UTF_8, CREATE, TRUNCATE_EXISTING);
} catch(IOException e) {
e.printStackTrace();
}
// log.info("batch file processing done");
});
}
}, "T1").start();
}解决方式也很简单,上述线程池并不是为我们这种IO密集型任务准备的,所以我们单独为其划分一个线程池出来处理这些任务。
private ThreadPoolExecutor asyncCalcThreadPool = new ThreadPoolExecutor(200, 200, 1, TimeUnit.HOURS, new ArrayBlockingQueue < > (50), new ThreadFactoryBuilder().setNameFormat("asynccalc-threadpool-%d").get(), new ThreadPoolExecutor.CallerRunsPolicy());
@GetMapping("wrong")
public int wrong() throws ExecutionException, InterruptedException {
return asyncCalcThreadPool.submit(calcTask()).get();
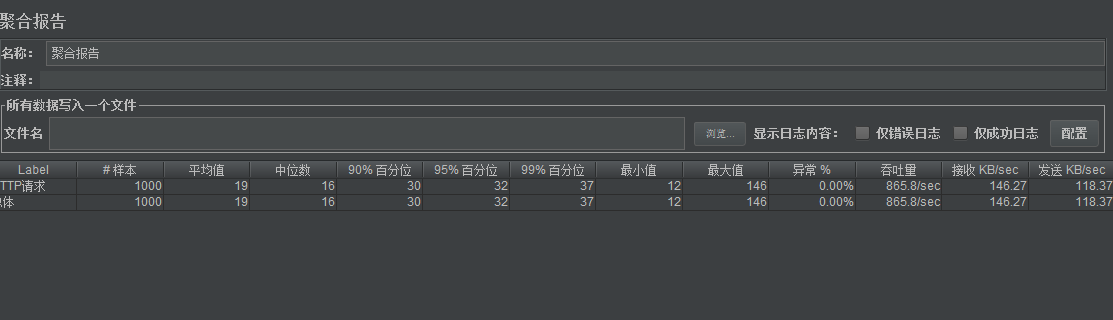
}经过压测可以发现性能明显上来了
小结
总结一下上述几个例子的经验:
避免使用Executors创建线程池。
确保线程确实被服用到。
确保在合适的场景使用合适的线程池:
texCPU密集型:若是CPU密集型,我们希望多利用CPU资源来处理任务,因为没有任何IO,理想情况线程数=CPU核心数即可,但是考虑到可能回出现某个意外情况导致线程阻塞,所以我们建议线程数=CPU核心数+1 IO密集型:IO密集型由于每个任务可能回出现IO导致任务阻塞,在单核情况下,我们建议: 线程数=IO时长/CPU计算耗时+1 若在多核的情况下,我们建议 线程数=CPU核心数 * (IO时长/CPU计算耗时+1) 但是具体情况还要具体结合压测结果进行响应调整。
参考文献
新手也能看懂的线程池总结(opens new window)
线程池系列之CallerRunsPolicy()拒绝策略 (opens new window)